강화학습: 파이썬으로 구현한 DQN
June 20, 2022, 11:50 p.m.
이번에는 DQN, Deep Q-Learning에 대해서 알아보겠습니다.
1. DQN
DQN은 Q-Learning을 인공 신경망을 이용해서 구현한 오프폴리시 알고리즘입니다. 이전에 알아본 딥살사 같은 경우 온폴리시 알고리즘인데요. 즉 학습이 정책에 영향을 받습니다. 행동하는대로 학습을 하게 되는 것이죠. 이렇게 되면 만약 초반에 탐험을 하다가 안좋은 방향으로 빠졌을 경우 그 상태에서 못벗어나는 경우가 생기게 됩니다.
그래서 큐러닝이라는 오프폴리시 알고리즘이 생기게 된 것이죠? 큐러닝에 대해서는 강화학습: 파이썬으로 구현하는 큐러닝, Q Learning 글을 참고하세요.
여기에 DQN은 한가지 추가적인 아이디어를 사용합니다. 바로 Experience Replay입니다. 우리말로 경험 리플레이라고 합니다. 에이전트가 환경을 탐험하며 얻는 샘플 (S, A, R, S')를 바로 학습에 사용하는 것이 아니라 리플레이 큐에 저장합니다. 그리고 어느정도 샘플이 쌓이면 큐에서 랜덤으로 샘플을 뽑아 학습에 사용하는 것이죠. 이 과정을 타임스텝마다 반복합니다.
그리고 큐에 샘플이 꽉 차게 되면 가장 먼저 들어온 샘플부터 지우고 새로운 샘플을 집어 넣습니다. 선입선출 (FIFO)이죠? 그래서 dequeue를 사용합니다.
왜 경험 리플레이를 사용할까요? 경험 리플레이를 사용하게 되면 샘플간의 시간 순서에 영향을 받지 않게 됩니다. 큐러닝 자체는 오프폴리시 알고리즘이긴 하지만 탐험을 하기 때문에 안좋은 상황에 빠져 벗어나지 못하면서 그 상황에 맞게 학습되는 경우가 있습니다. 매 타임스텝마다 학습을 진행하기 때문에 샘플간의 시간 순서도 학습에 영향을 주고, 안좋은 상황에 대해서만 학습이 계속 진행되게 되는 것이죠.
경험 리플레이를 사용하게 되면 큐에 담긴 샘플중에서 랜덤으로 뽑아 학습을 진행하기 때문에 샘플간의 시간적인 상관관계가 없어집니다. 훨씬 학습이 안정적이고 과적합 되지 않습니다. 그리고 큐에서 샘플을 하나만 뽑지 않고 여러개를 뽑아 학습을 진행하면 훨씬 안정적이겠죠?
마지막으로 DQN에서는 타깃 신경망이라는 개념을 사용합니다. 타깃 신경망을 이해하기 위해서 큐러닝에서 큐함수의 업데이트 식을 가져와 보겠습니다.
현재 신경망에서 출력되는 를 업데이트 목표(정답)인 에 만큼 다가간다고 이해하면 편합니다. 그렇지만 보시다시피 정답값을 구할 때도 신경망의 출력을 사용합니다. 신경망 자체의 출력값으로 신경망 자신을 다시 업데이트한다.. 정답도 계속 변하는데, 신경망 자체도 계속 변합니다. 이렇게 학습을 진행하게 되면 문제가 커질 것입니다. 이를 방지하기 위해 타깃 신경망이라는 개념을 도입했습니다.
신경망 A와 B가 있습니다. A는 타깃 신경망으로서 정답을 내는 신경망입니다. 이를 토대로 모델 신경망인 B를 학습시키죠. 학습을 진행하면서 일정한 간격마다 B를 A로 업데이트 시킵니다. 즉, 타깃 신경망을 업데이트 하는 것입니다. 이러한 방법으로 학습을 진행하게 됩니다.
Q-Learning에 인공신경망, 그리고 경험 리플레이와 타깃 신경망까지 여러 개념이 도입된 DQN에 대해서 알아보았습니다.
2. 파이썬으로 구현
그럼 이를 토대로 DQN을 파이썬으로 구현해보겠습니다. 위키북스의 파이썬과 케라스로 배우는 강화학습 책을 참고했습니다.
먼저 코드 전문을 보겠습니다.
import random
import numpy as np
from collections import deque
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.initializers import RandomUniform
import tensorflow as tf
class NN(tf.keras.Model):
def __init__(self, action_size):
super(NN, self).__init__()
self.fc1 = Dense(24, activation='relu')
self.fc2 = Dense(24, activation='relu')
self.fc_out = Dense(action_size, kernel_initializer=RandomUniform(-1e-3, 1e-3))
def call(self, x):
x = self.fc1(x)
x = self.fc2(x)
q = self.fc_out(x)
return q
class DQN:
def __init__(self, state_size, aciton_size):
self.state_size = state_size
self.action_size = aciton_size
self.discount_factor = 0.99
self.learning_rate = 0.001
self.epsilon = 1.0
self.epsilon_decay = 0.999
self.epsilon_min = 0.001
self.batch_size = 64
self.train_start = 1000
self.memory = deque(maxlen=2000)
self.model = DQN(self.action_size)
self.target_model = DQN(self.action_size)
self.optimizer = Adam(learning_rate=self.learning_rate)
self.update_target_model()
def update_target_model(self):
self.target_model.set_weights(self.model.get_weights())
def get_action(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
else:
q = self.model(state) #리스트 형태로 반환됨
return np.argmax(q[0])
def append_sample(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def train_model(self):
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
mini_batch = random.sample(self.memory, self.batch_size)
states = np.array([sample[0][0] for sample in mini_batch])
actions = np.array([sample[1] for sample in mini_batch])
rewards = np.array([sample[2] for sample in mini_batch])
next_states = np.array([sample[3][0] for sample in mini_batch])
dones = np.array([sample[4] for sample in mini_batch])
model_params = self.model.trainable_variables
with tf.GradientTape() as tape:
predicts = self.model(states)
one_hot_action = tf.one_hot(actions , self.action_size)
predicts = tf.reduce_sum(one_hot_action * predicts, axis=1)
target_predicts = self.target_model(next_states)
target_predicts = tf.stop_gradient(target_predicts)
max_q = np.amax(target_predicts, axis=-1)
targets = rewards + (1-dones) * self.discount_factor * max_q
loss = tf.reduce_mean(tf.square(targets - predicts))
grads = tape.gradient(loss, model_params)
self.optimizer.apply_gradients(zip(grads, model_params))
쪼오끔 기네요..
먼저 신경망을 선언하는 부분입니다. 따로 빼내서 신경망 구성을 편하게 했습니다. 컨볼루션 신경망(CNN)등을 사용할 수도 있게요. 딥마인드에서 Atari의 벽돌깨기 게임을 DQN으로 학습 시킬때도 CNN을 사용했답니다!
import random
import numpy as np
from collections import deque
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.initializers import RandomUniform
import tensorflow as tf
class NN(tf.keras.Model):
def __init__(self, action_size):
super(DQN, self).__init__()
self.fc1 = Dense(24, activation='relu')
self.fc2 = Dense(24, activation='relu')
self.fc_out = Dense(action_size, kernel_initializer=RandomUniform(-1e-3, 1e-3))
def call(self, x):
x = self.fc1(x)
x = self.fc2(x)
q = self.fc_out(x)
return q
간단한 3겹 신경망이빈다. 활성화 함수를 relu로 해주었다는점! 출력층의 가중치 초기화를 RandomUnifor을 이용해서 해주었습니다. 출력층의 초기값이 학습에 큰 영향을 주기 때문입니다.
그다음엔 모델 초기화 부분입니다.
class DQN:
def __init__(self, state_size, aciton_size):
self.state_size = state_size
self.action_size = aciton_size
self.discount_factor = 0.99
self.learning_rate = 0.001
self.epsilon = 1.0
self.epsilon_decay = 0.999
self.epsilon_min = 0.001
self.batch_size = 64
self.train_start = 1000
self.memory = deque(maxlen=2000)
self.model = NN(self.action_size)
self.target_model = NN(self.action_size)
self.optimizer = Adam(learning_rate=self.learning_rate)
self.update_target_model()
def update_target_model(self):
self.target_model.set_weights(self.model.get_weights())
각종 파라미터들을 초기화 해주었습니다. 여기서 batch_size가 한번 학습 큐에서 랜덤으로 뽑을 샘플의 크기입니다. 또한 train_start는 샘플이 어느정도 쌓였을 때 학습을 시작할지에 대한 값입니다.
또한 모델 신경망과 타깃 신경망을 각 생성해 주었네요. 또한 update_target_model로 두 신경망을 동일하게 만들어 주었습니다. 타깃 신경망을 업데이트하는 함수입니다.
다음은 행동을 가져오는 부분입니다.
def get_action(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
else:
q = self.model(state) #리스트 형태로 반환됨
return np.argmax(q[0])
탐험율에 따라 랜덤으로 행동을 반환하거나 신경망의 출력값을 기반으로 행동을 반환합니다.
마지막으로 제일 중요한 학습 부분입니다.!!
def append_sample(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def train_model(self):
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
mini_batch = random.sample(self.memory, self.batch_size)
states = np.array([sample[0][0] for sample in mini_batch])
actions = np.array([sample[1] for sample in mini_batch])
rewards = np.array([sample[2] for sample in mini_batch])
next_states = np.array([sample[3][0] for sample in mini_batch])
dones = np.array([sample[4] for sample in mini_batch])
model_params = self.model.trainable_variables
with tf.GradientTape() as tape:
predicts = self.model(states)
one_hot_action = tf.one_hot(actions , self.action_size)
predicts = tf.reduce_sum(one_hot_action * predicts, axis=1)
target_predicts = self.target_model(next_states)
target_predicts = tf.stop_gradient(target_predicts)
max_q = np.amax(target_predicts, axis=-1)
targets = rewards + (1-dones) * self.discount_factor * max_q
loss = tf.reduce_mean(tf.square(targets - predicts))
grads = tape.gradient(loss, model_params)
self.optimizer.apply_gradients(zip(grads, model_params))
먼저 append_sample() 함수로 에이전트가 행동을 할 때마다 얻은 샘플을 큐에 담아줍니다. 여기서 중요한 점은 done이라는 에피소드 종료 여부도 담는다는 점인데요 그 이유는 바로 밑에서 알아봅시다.
그다음 train_model()로 학습을 진행하는데요, 먼저 탐험율 epsilon을 decay 시킵니다. 그 다음 큐에서 앞서 지정해준 배치 크기만큼 샘플을 뽑아 S, A, R, S` 별로 배열을 새로 만들어 줍니다.
GradientTape을 열어주고 먼저 모델 신경망으로 예측값을 생성합니다. 그다음 타깃 신경망으로 정답값을 생성합니다. 그리고 나서 위에서 알아본 큐함수 업데이트 식을 적용해 모델 신경망을 학습합니다. 여기서 중요한 점은 max_q 값에 (1-done)을 곱해 에피소드가 끝난 경우에는 다음 행동이 없음을 반영합니다.
오류함수는 MSE를 사용하여 loss에 담아주었고 이를 기반으로 역전파를 적용합니다.
이렇게 DQN 모델을 파이썬으로 만들어 보았는데요, 이제 그럼 실제로 환경에 적용해볼까요?
3. 환경에 적용해보기
이번에는 OPENAI Gym 에서 제공하는 환경에서 DQN 모델을 적용해 보겠습니다. 코드 전문을 먼저 보겠습니다.
import numpy as np
env = gym.make('Acrobot-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DQN(state_size, action_size)
scores , episodes = [], []
score_avg = 0
EPISODES = 300
for e in range(EPISODES):
done = False
score = 0
state = env.reset()
state = np.reshape(state, [1, state_size])
while not done:
action = agent.get_action(state)
next_state, reward, done, info = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
reward = -(next_state[0][0]) - (next_state[0][0]*next_state[0][1] - next_state[0][2]*next_state[0][3])
score += reward
agent.append_sample(state, action, reward, next_state, done)
if len(agent.memory) >= agent.train_start:
agent.train_model()
state = next_state
if done:
agent.update_target_model()
print(f"episode : {e} | score : {score}")
scores.append(score_avg)
episodes.append(e)
차근차근 살펴보겠습니다. 먼저 환경과 에이전트를 선언하는 부분입니다.
import gym
env = gym.make('Acrobot-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DQN(state_size, action_size)
scores , episodes = [], []
score_avg = 0
EPISODES = 300
먼저 gym을 임포트 합니다. 패키지가 설치되어 있지 않다면 pip를 이용해 설치를 먼저 해야합니다. gym에서는 다양한 강화학습 환경을 제공하는데요, 이번 예시에서는 Acrobot-v1이라는 환경을 이용하겠습니다. Acrobot 환경은 관절이 1개 있는 작은 팔인데요, 이 팔의 끝이 일정 높이 이상이 되도록 올리는 것이 목표입니다. 아래의 Documentation을 확인해보세요.
환경을 가져온 뒤에는 환경에서 얻어오는 상태의 크기와 행동할 수 있는 행동의 크기를 받아옵니다. 공식 문서에 의하면 행동은 0, 1, 2 총 3가지를 할 수 있으며 상태는 5가지의 값을 가집니다.
그 다음 DQN 에이전트를 생성합니다. 앞서 받아온 상태와 행동의 크기를 넣어줍시다.
그리고 나서 에피소드별 점수를 담을 리스트와 변수, 그리고 학습을 진행할 에피소드를 담을 변수를 만들어 주었습니다.
두번째로 학습 부분입니다.
for e in range(EPISODES):
done = False
score = 0
state = env.reset()
state = np.reshape(state, [1, state_size])
while not done:
env.render()
action = agent.get_action(state)
next_state, reward, done, info = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
reward = -(next_state[0][0]) - (next_state[0][0]*next_state[0][1] - next_state[0][2]*next_state[0][3])
score += reward
agent.append_sample(state, action, reward, next_state, done)
if len(agent.memory) >= agent.train_start:
agent.train_model()
score_avg = score_avg * 0.9 + 0.1 * score
state = next_state
if done:
agent.update_target_model()
print(f"episode : {e} | score : {score_avg}")
scores.append(score_avg)
episodes.append(e)
학습할 에피소드만큼 for 문을 돕니다. 각 for 문 시작에는 환경을 초기화합니다. np.reshape을 이용해서 상태 배열의 차원을 늘려주었는데요, 이는 인공 신경망의 입력을 미니배치 형태로 넣어주기 때문이랍니다.
while 문을 이용해 에피소드가 종료될때 까지 반복합니다. 먼저 에이전트로부터 행동을 가져 온 후, env.step()을 이용해 한 타임스텝만큼 진행합니다. 환경은 반환값으로 다음 상태와 보상, 에피소드 완료 여부, 그리고 추가 정보를 반환합니다.
공식 문서를 확인해 보면 팔의 끝이 특정 높이에 도달하지 않았을 때는 무조건 보상을 -1을 주고, 도달 했을 경우 보상을 0을 받습니다. 이 상태로 학습을 진행해도 결국엔 학습이 되겠지만 보상에 정보가 너무 안 담겨 있습니다. -1과 0 대신에 팔의 높이를 보상으로 줘 보겠습니다.
공식 문서에 따르면 현재 팔의 높이는 -cos(theta1) - cos(theta2 + theta1)라는 공식으로 구할 수 있습니다. 다음 상태값을 이용해 팔의 높이를 계산해 주었고 이것을 보상으로 주었습니다.
보상 계산이 끝나면 해당 (S, A, R, S') 샘플을 큐에 저장합니다.
만약 큐에 있는 샘플의 양이 학습을 시작하기에 적당하다면, 에이전트의 학습을 진행합니다. 학습이 완료되면 평균 점수를 업데이트하고 현재 상태에 다음 상태값을 대입합니다.
마지막으로 다음 타임스텝으로 넘어가기 전에 에피소드가 완료되었다면, 타깃 신경망을 새로 업데이트하고 이번 에피소드의 정보를 출력하고 리스트에 저장하므로써 해당 에피소드를 완료합니다.
위의 코드를 실행해보면 아래와 같이 학습이 진행되는 모습을 볼 수 있을 거에요.
episode : 0 | score : -222.31742969530282
episode : 1 | score : -421.7609742050157
episode : 2 | score : -462.5983440207849
episode : 3 | score : -329.08065588434374
episode : 4 | score : -105.26780919838868
episode : 5 | score : -371.08929788838515
episode : 6 | score : -391.09647362839263
episode : 7 | score : -362.4835380561102
episode : 8 | score : -366.78375125093413
episode : 9 | score : -344.10040370227705
episode : 10 | score : -348.38217350843
episode : 11 | score : -339.84768687404556
episode : 12 | score : -340.45422684404696
episode : 13 | score : -339.67388984832917
episode : 14 | score : -340.7849434462208
episode : 15 | score : -338.30329897464594
episode : 16 | score : -340.2137310505206
episode : 17 | score : -338.92324335584004
episode : 18 | score : -339.4655561398538
episode : 19 | score : -337.95944728422796
episode : 20 | score : -338.54455836084577
episode : 21 | score : -339.71764679631616
episode : 22 | score : -277.8575276040694
episode : 23 | score : -365.1804705426609
episode : 24 | score : -350.75125805296994
episode : 25 | score : -338.1578657834814
학습이 완료되었다면 점수 리스트를 통해 학습 곡선을 그려보겠습니다.
import matplotlib.pyplot as plt
plt.plot(episodes, scores)
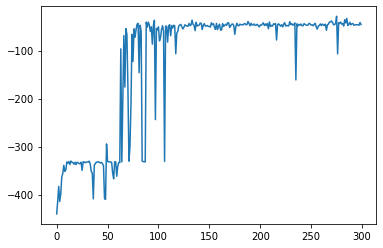
학습 곡선을 보면 처음에는 높이에 도달하지 못하다가 50~100 에피소드 사이에서 높이에 가끔 도달하는 모습을 볼 수 있으며 이를 기반으로 학습되어 150에피소드 이후로는 수렴하는 모습을 볼 수 있습니다. 학습이 잘 되었네요.
마지막으로 에이전트 학습 전과 학습 후 영상 보고 마무리하겠습니다.
강화학습 DQN