강화학습: 파이썬으로 구현한 ChopStick(젓가락 게임) 환경
June 23, 2022, 11:51 p.m.
이번에는 강화학습에 사용할 목적으로 어렸을때의 추억의 게임인 젓가락 게임을 만들어 보았습니다.
먼저 코드 전문을 보겠습니다.
import numpy as np
import pandas as pd
import time
from collections import defaultdict
import random
import os
class ChopStick:
def __init__(self):
self.matrix = [1, 1, 1, 1]
self.state = self.matrix.copy()
self.unavailable_reward = -1
self.winning_reward = 1
self.state_size = 4
self.action_size = 10
self.DELAY = 1
self.code_to_str_1 = [" ", " | ", " |/ ", " ||/", "||//"]
self.code_to_str_2 = [" ", " | ", " /| ", "/|| ", "//||"]
def reset(self):
self.matrix = [1, 1, 1, 1]
self.state = self.matrix.copy()
return self.state
def swap(self):
temp = self.matrix.copy()
self.matrix[0] = temp[3]
self.matrix[1] = temp[2]
self.matrix[2] = temp[1]
self.matrix[3] = temp[0]
def step(self, side, action, show=False):
reward = 0
next_state = self.state.copy()
done = False
active = True
if side==2:
self.swap()
if action==6: #각 행동에 대해서 행동이 불가능할경우 패널티
if self.matrix[0]==0 or self.matrix[2]==0:
reward+= self.unavailable_reward
active = False
else:
temp = self.matrix[0] + self.matrix[2]
if temp >= 5:
self.matrix[0] = 0
else:
self.matrix[0] = temp
elif action==7:
if self.matrix[1]==0 or self.matrix[2]==0:
reward+= self.unavailable_reward
active = False
else:
temp = self.matrix[1] + self.matrix[2]
if temp >= 5:
self.matrix[1] = 0
else:
self.matrix[1] = temp
elif action==8:
if self.matrix[0]==0 or self.matrix[3]==0:
reward+= self.unavailable_reward
active = False
else:
temp = self.matrix[0] + self.matrix[3]
if temp >= 5:
self.matrix[0] = 0
else:
self.matrix[0] = temp
elif action==9:
if self.matrix[1]==0 or self.matrix[3]==0:
reward+= self.unavailable_reward
active = False
else:
temp = self.matrix[1] + self.matrix[3]
if temp >= 5:
self.matrix[1] = 0
else:
self.matrix[1] = temp
else: # 내손에서 내손으로 옮기기
actDict = {0:-1, 1:-2, 2:-3, 3:1, 4:2, 5:3}
tempL = self.matrix[2] + actDict[action]
tempR = self.matrix[3] - actDict[action]
if tempL==self.matrix[3] and tempR==self.matrix[2]:
reward += self.unavailable_reward
active = False
elif tempL < 0 or tempR < 0 or tempR > 4 or tempL > 4:
reward += self.unavailable_reward
active = False
else:
self.matrix[2] = tempL
self.matrix[3] = tempR
if self.matrix[2]==0 and self.matrix[3]==0:
done = True
if self.matrix[0]==0 and self.matrix[1]==0:
done = True
reward += self.winning_reward
next_state = self.matrix.copy()
if side==2:
self.swap()
if show:
self.show(side, action, reward)
return next_state, reward, active, done
def show(self, side, act, reward):
os.system('cls')
print(f"S:{side},A:{act},R:{reward}")
print("----------")
print(" [] [] ")
print(f"{self.code_to_str_2[self.matrix[0]]} {self.code_to_str_2[self.matrix[1]]}")
print("")
print("")
print("")
print(f"{self.code_to_str_1[self.matrix[2]]} {self.code_to_str_1[self.matrix[3]]}")
print(" [] [] ")
print("----------")
time.sleep(self.DELAY)
0. 개요
젓가락 게임을 프롬프트로 진행할 수 있도록 간소화 했습니다. 환경을 실행하면 아래와 같은 화면이 출력됩니다.
S:2,A:6,R:0
----------
[] []
| |
| |/
[] []
----------
두 명의 플레이어가 진행합니다. side1과 side2가 마주보고 손가락을 내밀고 있네요. 밑쪽이 side1입니다. side1 기준으로 설명하겠습니다. 각 상태에서 할 수 있는 행동의 수는 0~9까지 10개입니다. 먼저 0에서 5까지는 자신의 손에서 손으로 움직이는 행동입니다.
0, 1, 2는 왼손에서 오른손으로 손가락을 1개, 2개, 3개 전달합니다. 3, 4, 5는 오른손에서 왼손으로 손가락을 1개, 2개, 3개 전달합니다.
6에서 9까지는 상대방의 손을 치는 행위입니다.
6은 자신의 왼손으로 상대의 오른손을 칩니다.
7은 자신의 왼손으로 상대의 왼손을 칩니다.
8은 자신의 오른손으로 상대의 오른손을 칩니다.
9는 자신의 오른손으로 상대의 왼손을 칩니다.
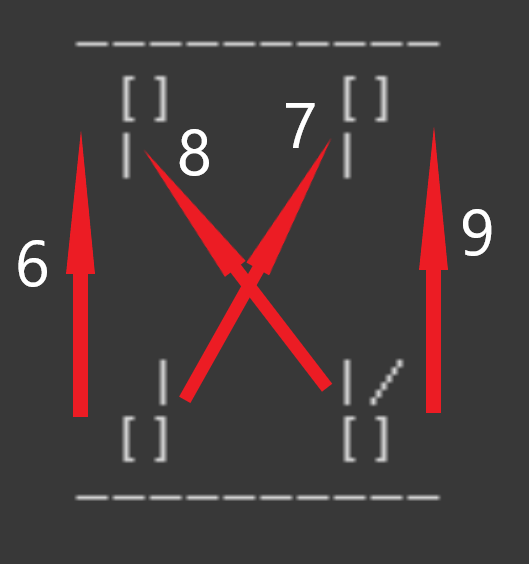
여기서 예를들어 왼손에 손가락이 1개밖에 없는데 오른손으로 손가락 3개를 옮기는 3번 행동을 하면 무효행동이 됩니다. 또한 단순히 오른손과 왼손의 손가락을 바꾸는 행위도 할 수 없습니다. 예를들어 왼손에 2개, 오른손에 1개가 있는데 0번행동을 하여 왼손에 1개, 오른손에 2개가 된다면 무효행동이 됩니다.
현재 상태는 길이가 4인 리스트로 반환됩니다. 각각의 값은 해당하는 손의 손가락 개수입니다.
[side1 왼손, side1 오른손, side2 오른손, side2 왼손]
상세한 설명보다는 사용법을 위주로 설명하겠습니다. 파이썬으로 이루어진 강화학습 환경들의 관습을 이어, reset(), step() 만으로 작동이 가능하도록 만들었습니다.
1. 선언
env = ChopStick()
환경 초기화에는 특별한 매개변수가 필요 없습니다.
2. 초기화
state = env.reset()
환경을 초기화 하고 현재의 상태를 반환합니다.
3. 행동하기
next_state, reward, active, done = env.step(side, action)
step(side, aciton)을 통해서 한 번의 행동을 할 수 있습니다. side는 1 또는 2가 될 수 있습니다. 만약 side가 2라면 2의 입장에서 행동을 행해야 합니다.
반환값으로 다음상태값(next_state), 보상(reward), 무효행동여부(active), 게임 완료(done) 여부를 받습니다. 보상은 승리했을 경우 1을 받습니다. 그 외에는 0을 받습니다. 또한 무효한 행동을 했을 경우에 -1을 받습니다. 무효행동여부는 무효행동일 경우 False, 유효한 행동일 경우 True를 받습니다. 게임이 완료되면 done은 True가 되며 그렇지 않을 경우 done은 False가 됩니다.
간단하게 에이전트와 사용자가 대결하는 코드를 마지막으로 마치겠습니다.
env = ChopStick()
agent = AI()
AGENTTURN = True
while True:
state = env.reset()
agent.epsilon = 0
input("PRESS ENTER TO START")
done = False
while not done:
if AGENTTURN:
action = agent.get_action(state)
next_state, reward, active, done = env.step(2, action, True)
else:
action = int(input("행동을 입력하세요 :"))
next_state, reward, active, done = env.step(1, action, True)
if not active:
continue
if AGENTTURN:
print(f"에이전트는 {action} 행동을 했습니다.")
else:
print(f"당신은 {action} 행동을 했습니다.")
if done:
if reward > 0:
if AGENTTURN:
print("패배....")
else:
print("승리!!!!")
else:
print("무승부")
state = next_state
AGENTTURN = not AGENTTURN
직접 제작한 다른 강화학습 환경은 저의 깃허브 리포지토리를 확인하세요!
강화학습