객체 탐지 알고리즘 YOLO 이론적 배경
Nov. 4, 2022, 5:08 p.m.
컴퓨터 비전에서 이미지 속 특정 객체의 위치와 크기를 탐지하는 일은 아주 중요한 작업이다. 자율 주행에서는 물론 수많은 작업에 사용 되기 때문이다.
.
어떤 이미지 자체의 종류를 판별하는 ImageNet 대회처럼 분류 문제는 오래 전부터 연구되어왔고 그에 따른 모델이 상당히 많이 개발되었다. 그러나 객체를 탐지하는 것은 아예 다른 차원의 문제이다.
.
훨씬 복잡한 출력과 계산이 요구되며, 또한 사용되는 도메인이 정적인 곳이 아니라 움직이는 차량에서의 객체 탐지와 같은 실시간 작업이 필요한 분야이기 때문에 모델의 추론 속도 또한 굉장히 중요하다. 오늘 소개할 알고리즘은 YOLO이지만, FAST-R-CNN 이라는 더욱 정확하고 빠른 모델이 있으며 이 또한 실시간으로 최적화되고 발전되어가는 중이다.
.
YOLO 또한 이름과 같이 (You Only Look Once) 굉장히 빠른 속도로 객체 탐지를 할 수 있게 된 중요한 알고리즘이다.
1. YOLO의 경계 박스 개념

YOLO는 이미지 위에 w * h 크기의 그리드를 만든다. 그리고 그리드 안의 각 칸에서 B개의 경계 상자를 정의 한다. 즉 한 이미지에서 총 w * h * B 개의 경계 상자를 추론한다.
.
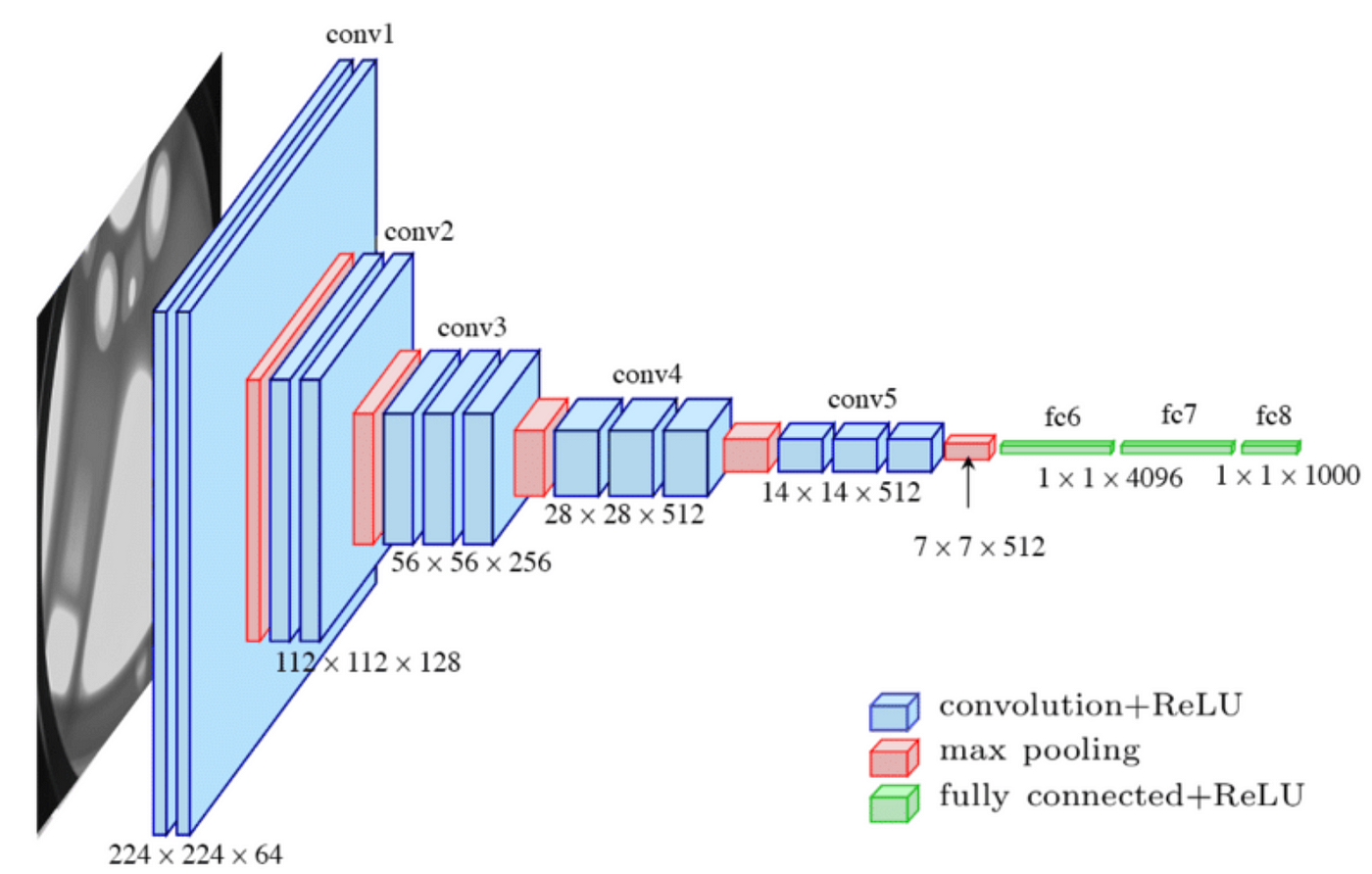
추론을 위해서 먼저 YOLO의 백본 네트워크에서 이미지를 넣고 출력으로 w * h * D의 특징 볼륨을 받는다. 여기서 백본 네트워크는 다양한 아키텍쳐들에서 마지막 계층을 제거한 네트워크이다. YOLO 논문에서는 VGG-16을 사용하였다고 한다.
.
특징 볼륨에서 D는 각 그리드 별 경계 상자에 대한 내용을 담고 있다. D는 아래와 같이 다시 표시할 수 있다.
여기서 는 각 그리드 별 경계 상자의 수를 의미한다. 는 클래스의 수를 의미한다. 클래스란 탐지할 객체 종류의 수라고 생각하면 된다. 마지막으로 가 더해졌는데 이는 경계상자를 정의하는 5가지 수치(를 말한다. 아래에서 자세히 설명하겠다.
, 는 경계 상자의 중심 좌표를 정한다.
, 는 경계 상자의 높이와 너비를 정한다.
는 해당 객체가 경계 상자 안에 있다고 확신하는 신뢰도를 의미한다.
.
여기서 중요한 점이 있다. 경계 상자를 정의하는 5가지 수치가 직접적으로 경계 상자의 크기를 정하는 것이 아니다. 그렇게 되면 학습이 잘 되지 않기 때문이다. 학습이 잘 되기 위해서 기본 가이드라인이 되는 경계 상자가 있다. 이것을 앵커 박스라고 한다.
논문에서 이 앵커박스는 학습을 진행할 도메인에 맞게 정하라고 한다. 예를 들어 축구 경기장에서 선수들을 인식하는 작업이라면 사람의 크기에 맞게 세로로 긴 직사각형 몇 개를 앵커 박스로 만들면 될 것이다.
그렇다면 경계 상자를 정의하는 5가지 수치와 앵커박스로 실제 경계 상자를 어떻게 정의할까? 그 수식은 아래와 같다. , 는 그리드 상의 좌표이다. ( (0, 0) 부터 (w-1, h-1)까지 ) , 는 앵커박스의 너비, 높이이다.
, 는 경계 박스의 중심좌표, , 가 경계 박스의 너비, 높이이다.
.
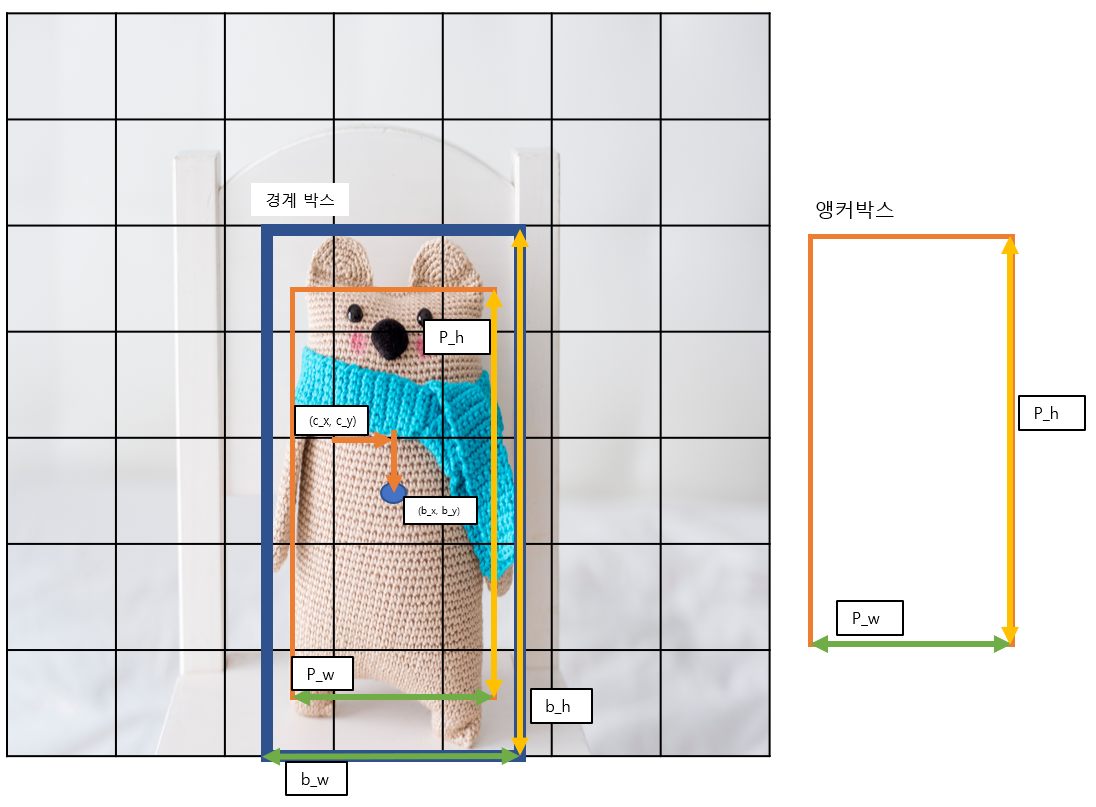 이런 식으로 백본 네트워크의 출력을 경계박스의 너비, 높이로 바꾼다.
이런 식으로 백본 네트워크의 출력을 경계박스의 너비, 높이로 바꾼다.
.
2. 경계 박스 사후 처리 계산
바뀐 경계 박스를 모두 사용할 수는 없다. 신뢰도가 낮은 경계 박스도 있기 때문. 그렇기 때문에 신뢰도가 낮은 경계 박스를 임계값을 정해서 걸러내는 작업이 필요하다.
.
그러기 위해서 각 경계 박스의 클래스별 점수를 구한다. 점수는 경계 상자의 신뢰도 c 와 클래스 별 확률을 곱해서 구한다. 그러면 한 경계 상자마다 클래스별 점수를 구할 수 있다.
그 다음에 임계값을 정해 그보다 큰 점수를 가진 클래스만 살린다. 이때 여러 클래스가 살아남으면 그 중에서 높은 점수인 클래스를 살린다.
이렇게 되면 살아남은 경계 상자는 한 가지 클래스를 예측하는 상자가 된다.
.
아직 끝난 것이 아니다. 어떤 객체가 여러 그리드 위에 걸쳐 있게 된다면 해당 객체를 감지한 경계 박스가 여러개가 될 수 있다. 우리는 그 중에서 제일 객체와 맞는 경계상자 하나만 놔두고 걸러내야 한다. 이 과정을 NMS(non-maximum suppression) 혹은 비최댓값 억제라고 한다.
.
말 그대로 확률이 가장 높은 상자를 택하고 그 상자와 곂치는 상자들을 제거하는 과정이다.
모든 상자를 점수가 가장 높은 순으로 배열 한 뒤 가장 큰 상자를 고르고 다른 상자들과 비교하며 일정 임계값 이상 곂치는 상자들은 제거한다. 이를 통해 같은 객체를 감지한 상자는 1개만 남길 수 있다.
이때 상자가 얼마나 곂쳤는지 판별하는 지표로써 IoU(Intersection over Union) 라는 것을 사용한다.
Iou란 두 영역의 교집합을 합집합으로 나눈 것이다. 식으로 나타내면 아래와 같다.
.
이런 식으로 사후 처리를 통해서 백본 네트워크에서 출력된 데이터를 의미있는 경계 상자만 얻을 수 있다.
.
다시 한번 YOLO의 추론 단계를 정리하자면 아래와 같다.
- 입력 이미지를 CNN 백본 네트워크에 넣어 특징 볼륨을 얻는다.
- 추가 네트워크를 통해 경계 상자에 대한 정보를 얻는다.
- 이를 바탕으로 경계 상자의 좌표를 얻는다.
- 사후 처리를 통해 의미있는 경계 상자만 남긴다.
.
3. YOLO 학습 시키기
YOLO는 출력 값이 상당히 복잡하기 때문에 학습이 잘 되게 하려면 역시 손실 함수를 잘 정의해야 한다. YOLO의 손실 함수는 꽤나 복잡한데 천천히 살펴보도록 하자.
YOLO의 손실 함수는 아래의 3가지에 대한 손실을 담는다.
- 경계 상자의 정확도
- 객체 신뢰도
- 클래스 분류
먼저 경계 상자의 정확도를 예측하기 위한 손실 함수에 대해서 알아보자. 아래의 두 식의 합이다.
첫번째 수식은 경계 상자의 중심 좌표의 오차를 계산한 식이고, 두번째 수식은 경계 상자의 너비와 높이의 오차를 계산한 식이다. 여기서 너비와 높이의 오차를 계산할 때 루트를 씌운 이유는 작은 상자 일 때 오차를 더 크게 패널티를 부여하기 위해서이다.
.
여기서 특이한 항이 있는데 바로 이는 지시 함수(indicator function) 이라고 하는데, 여기서는 해당 객체를 포함하면서 IoU가 가장 높은 상자일 때만 1이 된다. 해당 상자가 실제로 해당 객체를 탐지했을 때만 의미가 있게 만들기 위해서이다.
.
마지막으로 는 손실에 가중치를 부여해서 최종 손실에서 경계상자 손실에 얼만큼 중요도를 부과할 지 정할 때 사용한다.
.
두번째로는 객체의 신뢰도에 관한 손실 함수이다. 아래 두 식의 합이다.
여기서는 noobj 일때의 지시함수도 나오는데 이 지시함수는 어떤 객체도 탐지하지 못하고 또한 어느 다른 객체 상자와 많이 곂치지 않았을 때를 말한다.
.
마지막으로 클래스 분류 손실이다.
.
앞서 말했듯 전체 손실은 위의 식들의 합이다.
.
이렇게 오늘은 객체 탐지 알고리즘인 YOLO에 대해서 이론적인 부분을 알아봤다. 나도 공부하면서 끄적여 본 건데 실제로 구현을 해 보고 싶다.
객체탐지 YOLO