Yolov5 Custom Dataset으로 학습시키고 사용하기
Aug. 24, 2023, 10:54 p.m.
최근에 동아리 프로젝트로 Yolo를 사용할 일이 있었다. yolov5, yolov8은 Colab환경에서 쉽게 학습시킬 수 있는 Pipeline이 제공되고 있어서 쉽게 학습시키고 배포할 수 있었다. 이번에 yolov5를 학습시키고 배포했던 과정을 정리해 보려고 한다.
1. 데이터 준비하기 - Roboflow
.
학습 데이터는 Roboflow사이트를 통해서 준비한다. Roboflow 사이트에는 이미 사람들이 올려놓고 Annotation까지 해놓은 데이터가 많고, 직접 이미지나 동영상을 올려서 바로 Annotation을 할 수 있는 환경을 제공해 준다.
.
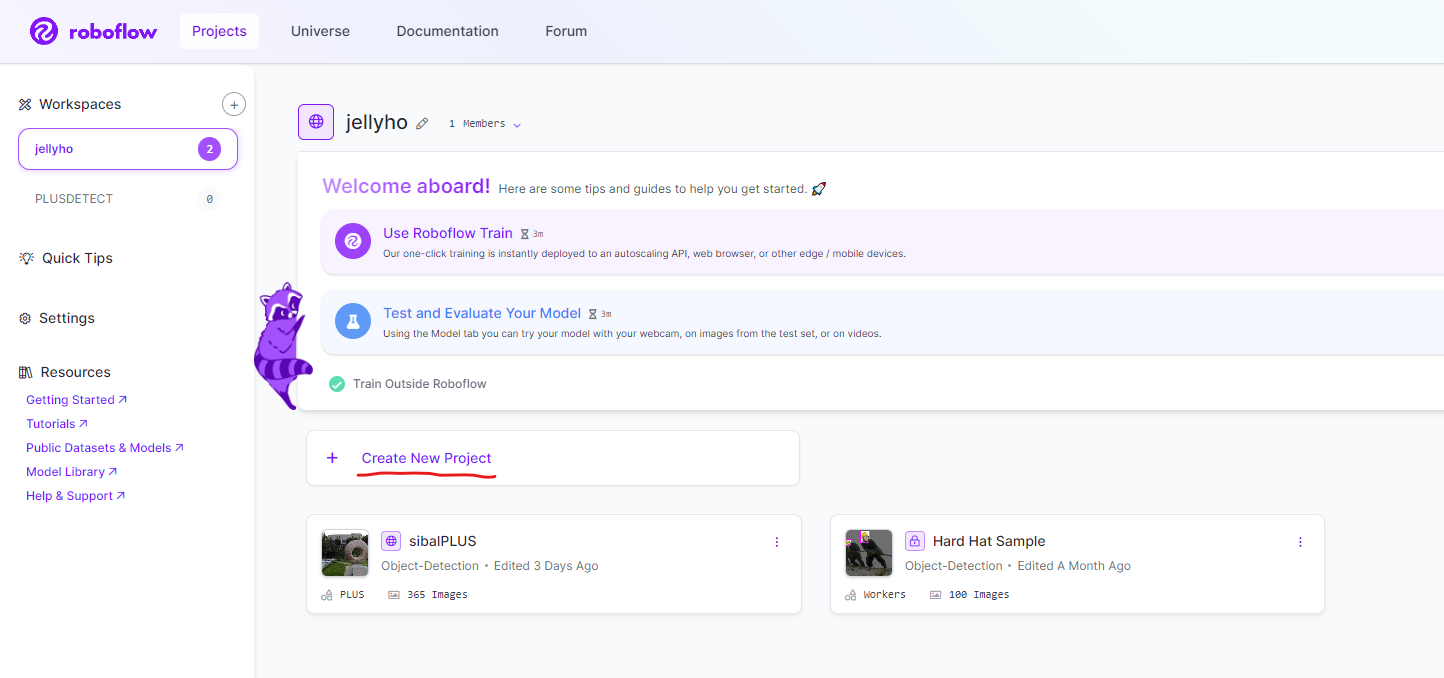
먼저 roboflow.com에 들어가서 Sign in 을 해준다. 그 다음 Create New Project를 눌러준다.
.
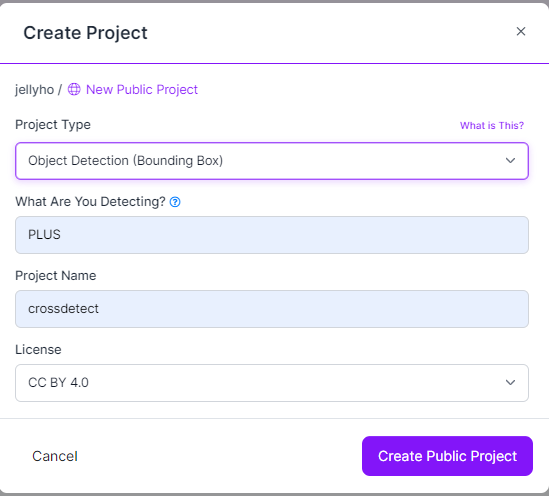
나는 검정색 십자가 마커를 인식하는 모델이 필요했기 때문에 아래와 같이 입력했다. 모두 입력하고 Create Public Project를 누르자.
.
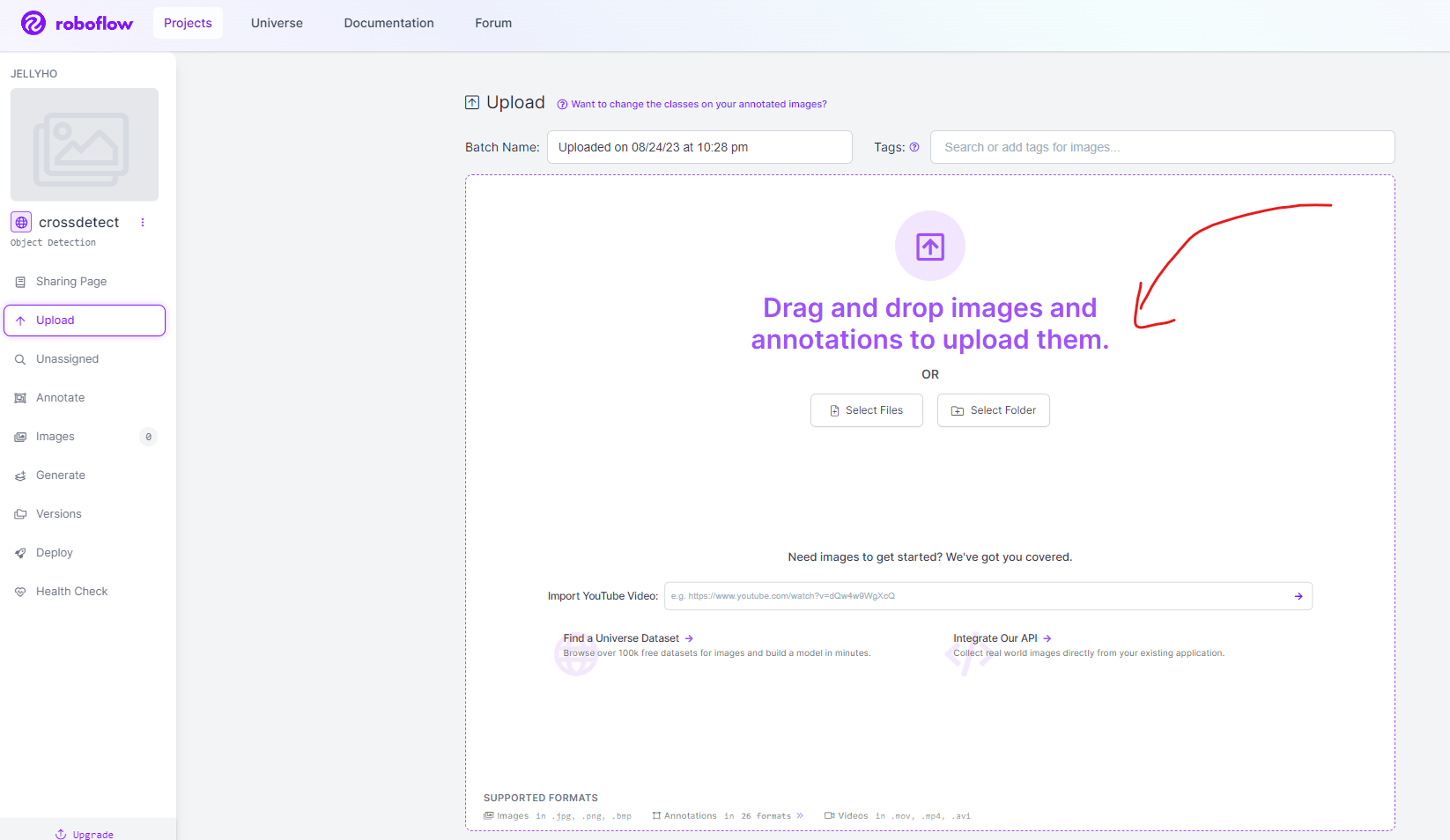
아래와 같이 화면이 나올 것이다. 직접 Annotation 할 이미지나, 유튜브 영상 링크를 올린다.
.
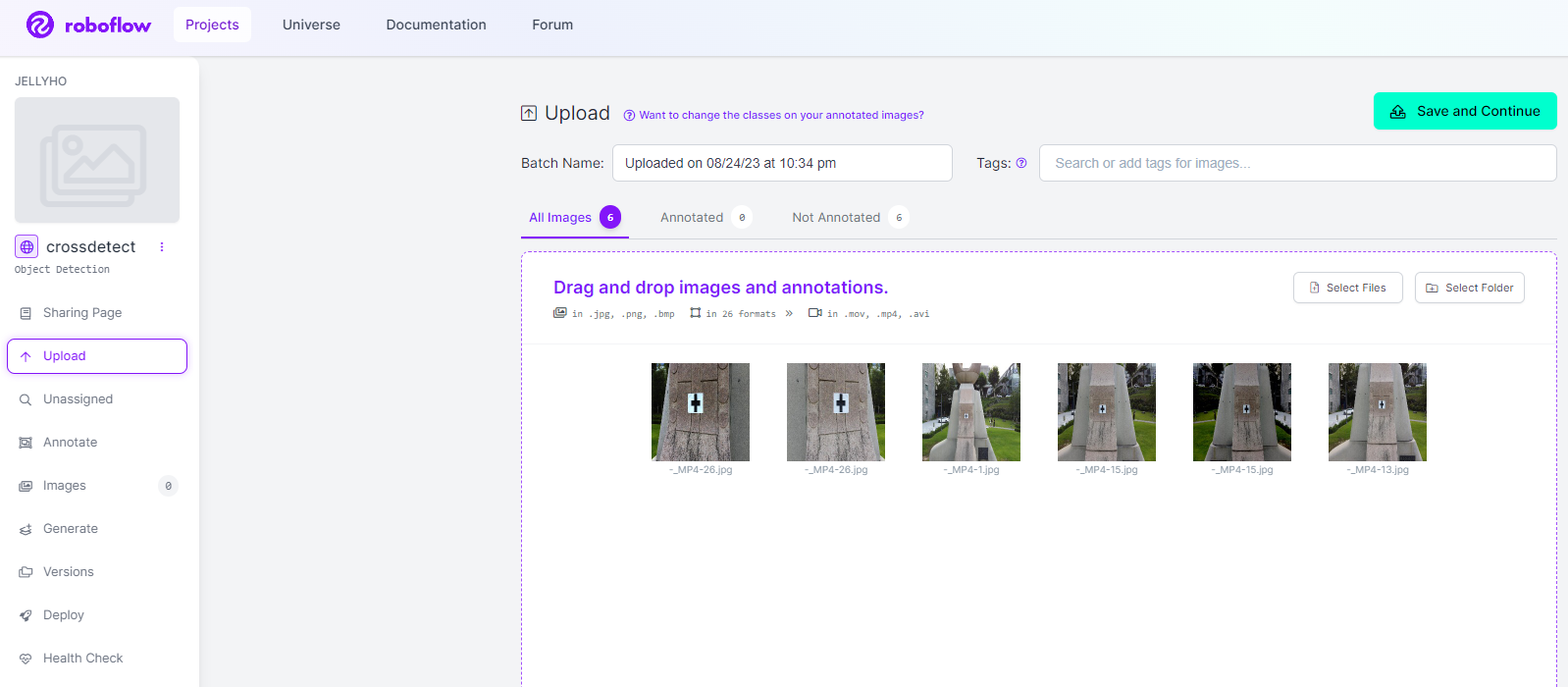
올리고 나면 이렇게 이미지가 추가된 모습을 볼 수 있을 것이다. 유튜브 영상 링크를 올린 경우 샘플링 주기 등을 설정해 주면 된다. Save and Continue를 누르자.
.
오른쪽에 이미지를 Assign하라고 나온다. 이때 Annotation할 추가적인 사람을 추가할 수 있다. 이미지가 많을 경우 사람을 초대해서 분업하는게 나을 것이다. Assgin Images를 누르자.
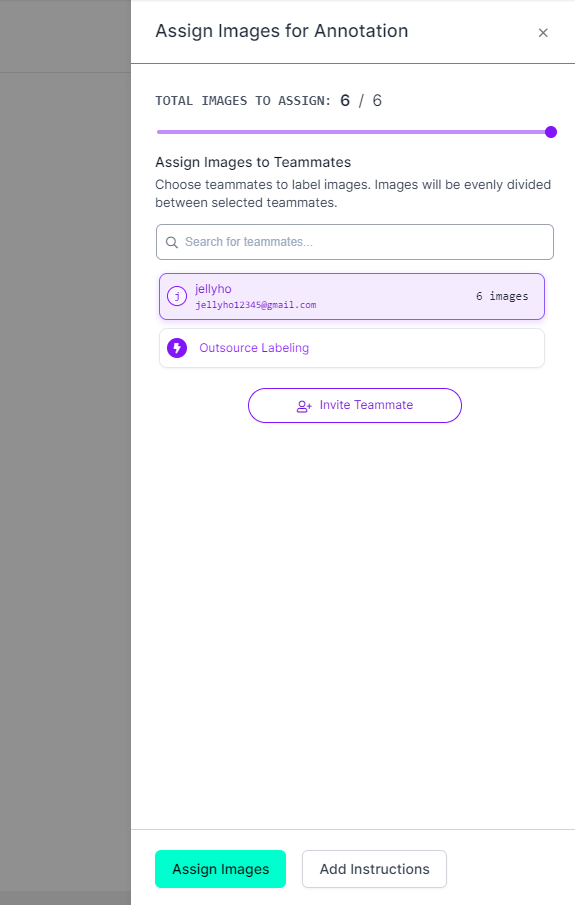
.
우측 위에 Start Annotating 버튼이 있을 것이다. 노가다 시작이다!!
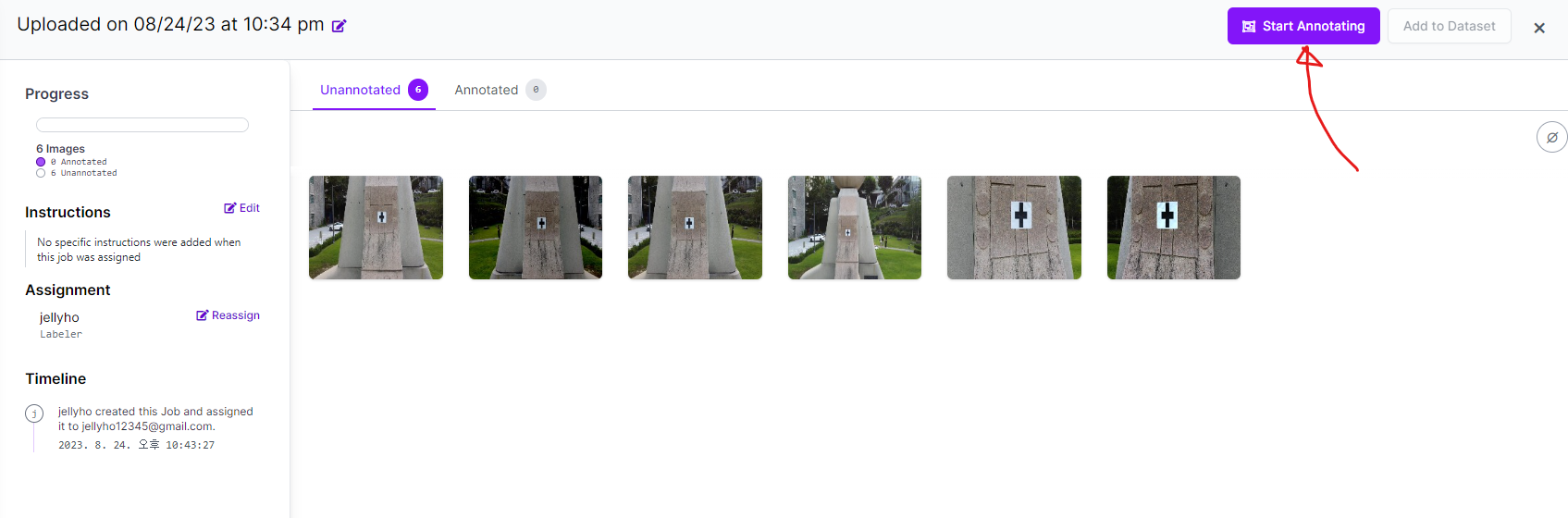
.
아래 사진 처럼 Bounding Box를 그리고 좌측 위에 나타나는 창에 Class 이름을 입력해주고 Save를 누른다. 당연히 클래스를 여러개 만들 수도 있다.
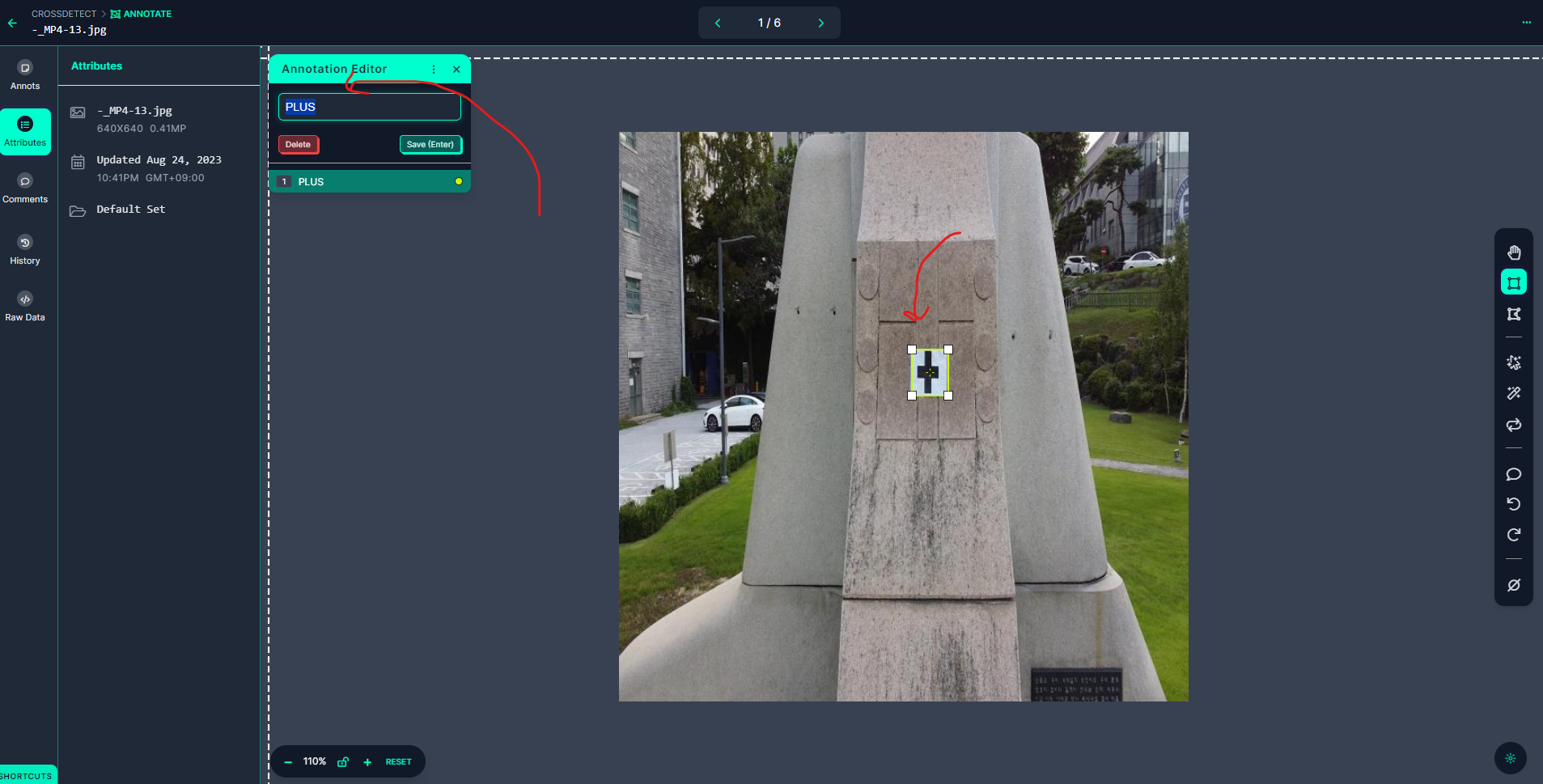
.
Annotation을 완료 했으면 우측 상단의 Add Images to Dataset를 누른다. 누르면 Train, Test, Valid 비율을 나누는 화면이 나온다. 지정해주고 넘어가자.
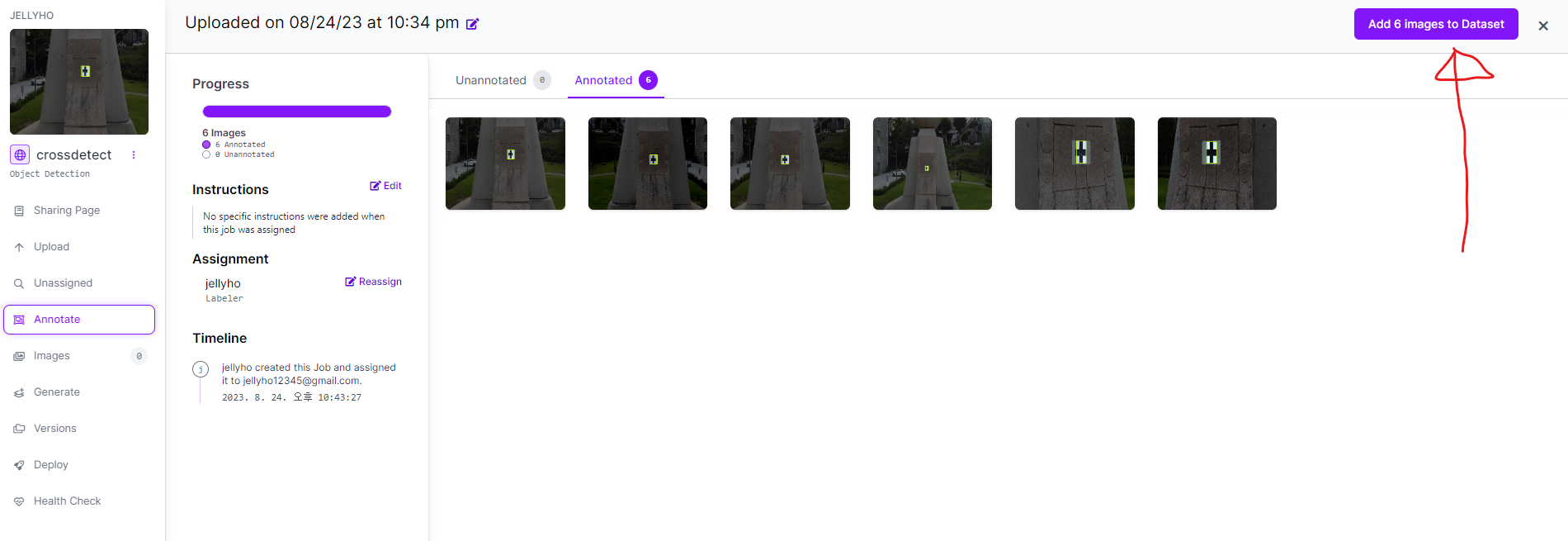
.
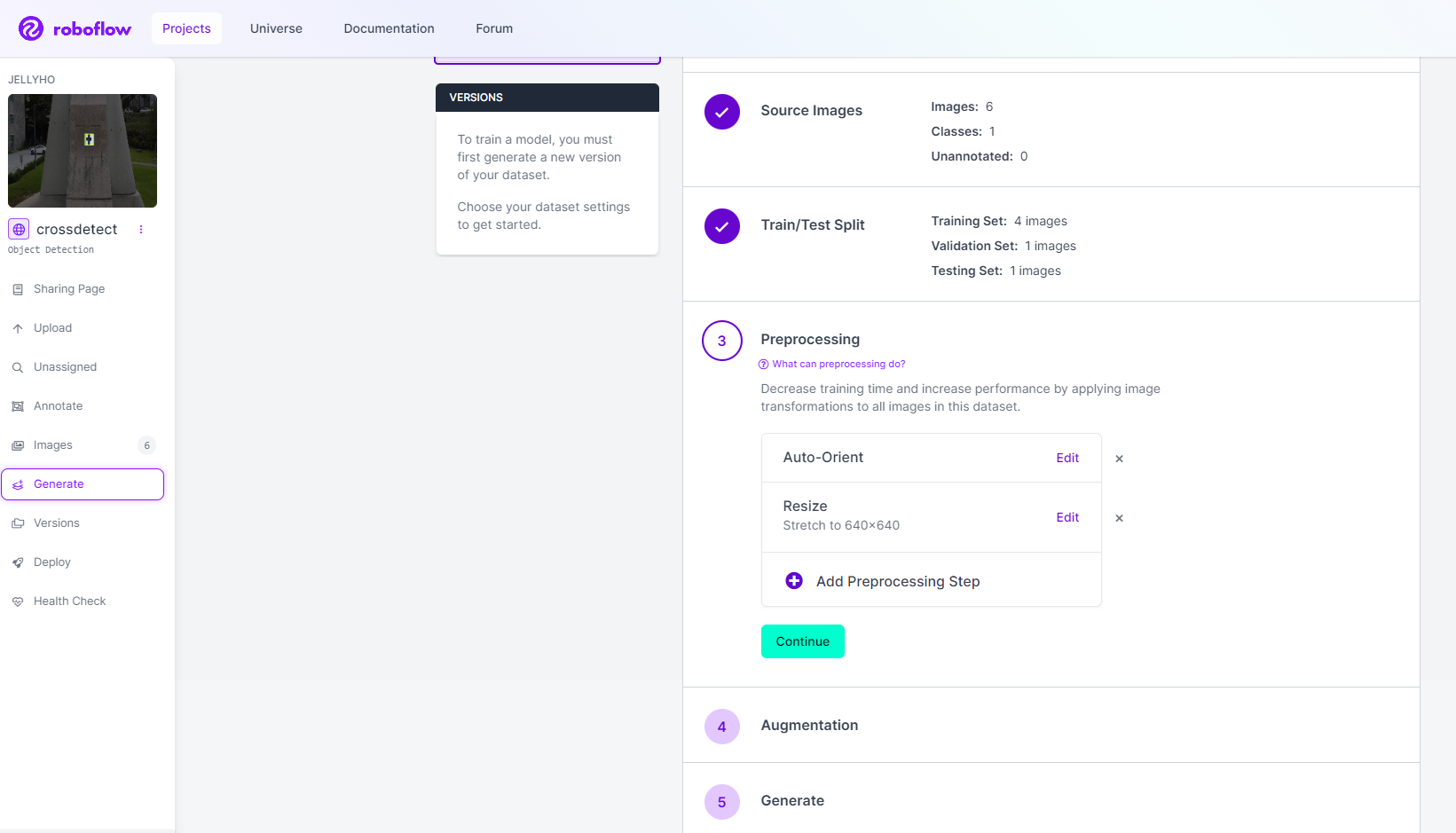
이제 데이터셋은 완성했다. 내보내기만 하면 된다. 좌측 툴바에 Generate 버튼을 누르면 아래와 같은 화면이 나올 것이다.
.
여기서 각종 Preprocessing과 Augmentation 설정을 해줄 수 있다. 이것까지 자동으로 해주니 얼마나 편한지... 설정이 다 되었으면 Generate를 누르면 된다.
.
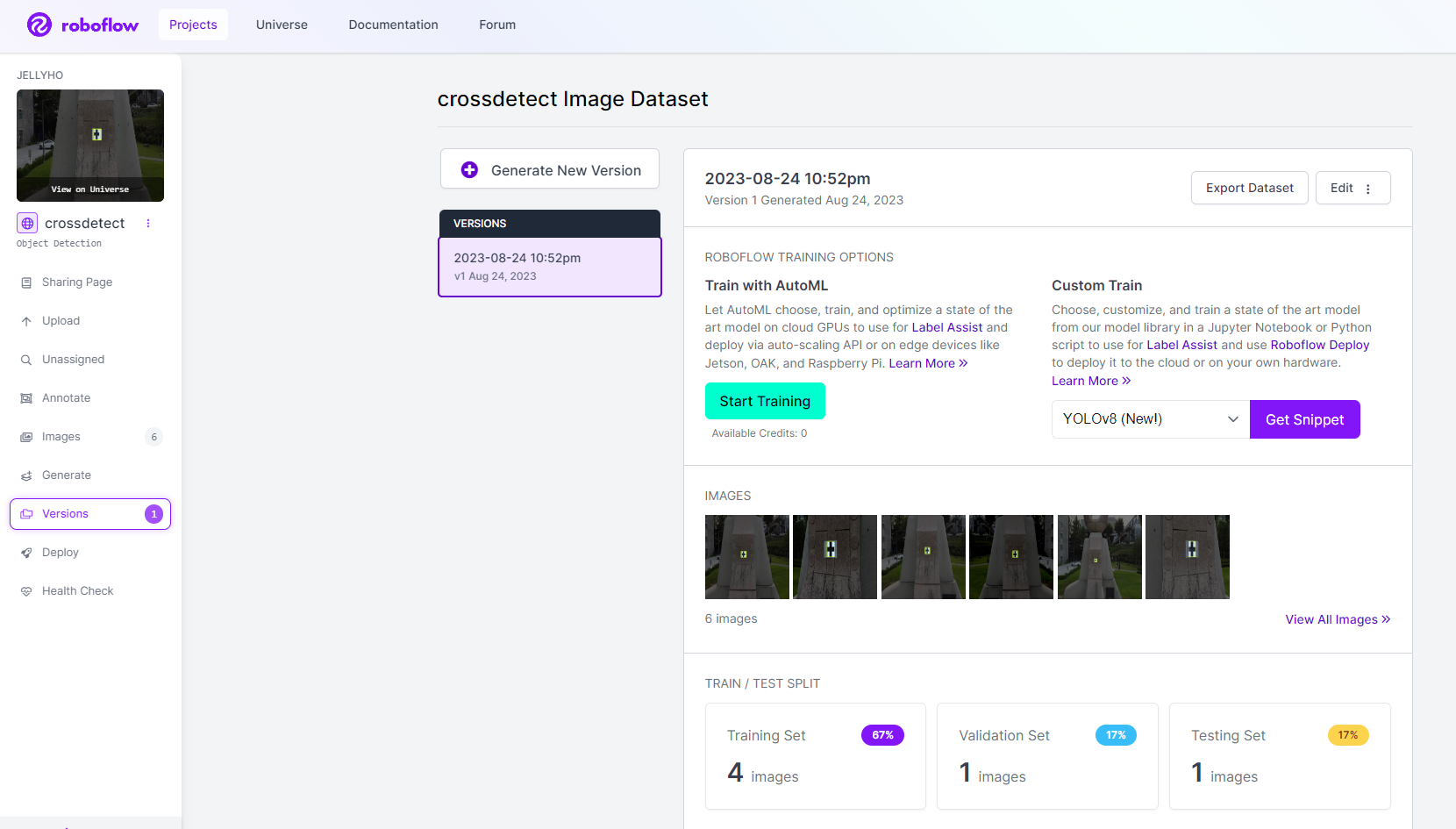
아래와 같이 나오면 데이터셋 만들기 성공이다.
.
2. 코랩에서 학습 시키기
.
자 이제 학습시킬 차례다. Colab에서 간단하게 학습시킬 수 있도록 코드가 제공되어있다. 아래 링크를 누르면 이동할 수 있다. 새 창으로 열기 바란다. .
.
본격적으로 학습을 시작하기 전에 먼저 Roboflow에서 데이터를 가져올 준비를 해야한다. 이전에 만들어 놓은 데이터셋에 들어가서 Versions에 들어가면 우측 상단에 Export Datasets 버튼이 있을 것이다.
.
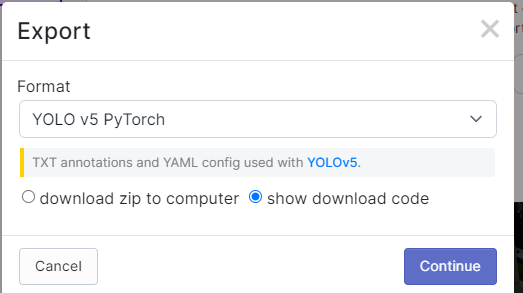 YOLO v5 Pytorch를 누르고 Show Download Code를 선택하고 Continue를 누른다.
YOLO v5 Pytorch를 누르고 Show Download Code를 선택하고 Continue를 누른다.
.
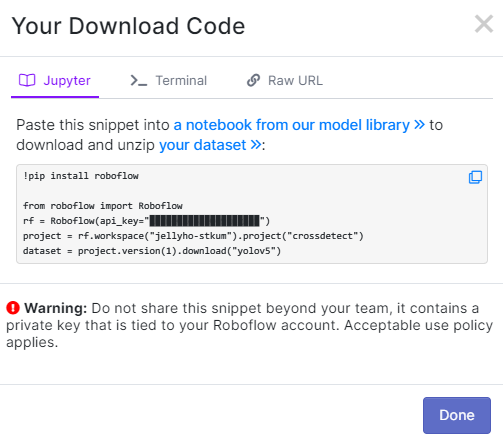 그러면 이렇게 코드 스니펫이 나올 것이다. 복사해두자.(외부에 공개되면 좋지 않으니 조심하자)
그러면 이렇게 코드 스니펫이 나올 것이다. 복사해두자.(외부에 공개되면 좋지 않으니 조심하자)
.
복사를 했다면 다시 Colab으로 돌아오자.
.
위에서부터 셀을 하나씩 실행하면 된다.
.
실행하다 보면 아래와 같이 데이터셋을 불러오는 부분이 있는데. 그림처럼 X 쳐진 셀은 실행하지 말고, 밑에 초록색으로 주석 된 부분에 이전에 복사했던 데이터셋 다운로드 코드 스니펫을 붙여넣고 실행한다.
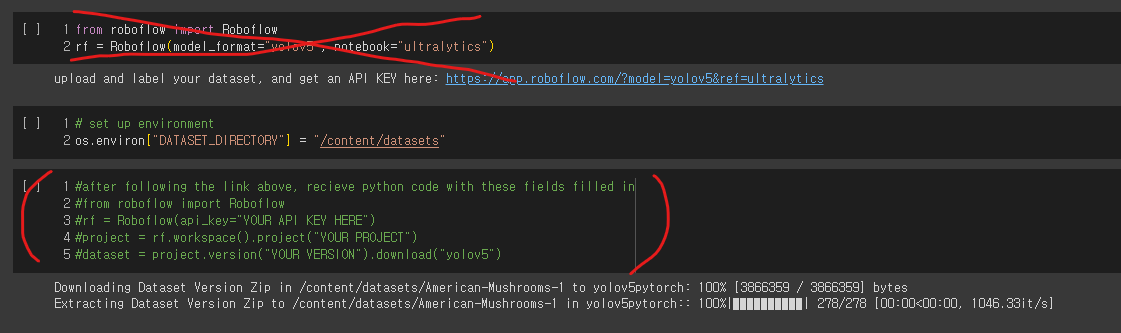
.
데이터셋 다운로드가 완료 되었다면, 이제 학습을 시키면 된다. 학습 시 여러가지 설정을 해줄 수 가 있는데, 먼저 --img 416과 같이 입력 이미지의 크기를 지정해 줄 수 있다. 또한 배치 사이즈나 에폭 수도 조정해 줄 수 있다. 여기서 중요한 것은 --weights 옵션이다. yolov5n.pt부터 ~yolov5x.pt 까지 모델의 크기를 달리 하여 학습을 시킬 수 있다. 마지막으로 --cache 옵션은 데이터셋을 메모리에 올려두고 학습을 진행 할 수 있도록 하는 옵션이다.
.
학습을 진행하고 학습이 완료되면 이제 모델을 Export 할 차례이다.
.
Export 시에는 아래와 같이 코드를 작성해 주면 된다.
!python export.py --weights ./runs/train/exp/weights/best.pt --include onnx --optimize --simplify --int8
학습이 완료된 .pt 파일을 불러와서 다양한 형식으로 내보낼 수 있다. 위의 코드는 onnx 런타임용으로 내보낸 모습이다.
.
Export가 완료되면 Colab에서 다운로드하는 것을 잊지 말자.
3. Inference 하기
이제 모델이 학습되고 준비되었다. 이제 사용하는 일만 남았다.
.
인퍼런스는 말보다 바로 코드를 보여주는 것이 나을 듯 하다.
import torch
import cv2
from torch.autograd import Variable
import time
# model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5nV2.pt', force_reload=True)
model = torch.hub.load('.', 'custom', 'yolov5nV4.onnx', source='local', force_reload=True)
model.iou = 0.5
input_file = 'yaloo.mp4'
output_file = 'yaloo_yolov5nV4_onnx.mp4'
cap = cv2.VideoCapture(input_file)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
resolution = (int(cap.get(3)), int(cap.get(4)))
out = cv2.VideoWriter(output_file, fourcc, 24.0, resolution)
while cap.isOpened():
start = time.time()
ret, frame = cap.read()
if not ret:
break
# 프레임을 화면에 표시합니다.
# cv2.imshow('Webcam', frame)
# frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = model(cv2.resize(frame, (640, 640)))
for volume in results.xyxy[0]:
xyxy = volume.numpy()
# print((xyxy[0], xyxy[1]), (xyxy[2], xyxy[3]))
xyxy[0] = xyxy[0] / 640 * resolution[0]
xyxy[2] = xyxy[2] / 640 * resolution[0]
xyxy[1] = xyxy[1] / 640 * resolution[1]
xyxy[3] = xyxy[3] / 640 * resolution[1]
cv2.rectangle(frame, (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])), color=(0, 255, 0), thickness=2)
cv2.putText(frame, f'{xyxy[4]:.3f}', (int(xyxy[0]), int(xyxy[1])), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(0, 255, 0), thickness=2)
dt = (time.time() - start) * 1000
cv2.putText(frame, f'Inference : {dt:.1f}ms', (0, 100), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1,
color=(0, 0, 255), thickness=2)
# 결과를 출력 동영상 파일에 저장합니다.
out.write(frame)
cv2.imshow('Frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
print(f'{dt}')
cap.release()
out.release()
cv2.destroyAllWindows()
위의 코드는 torch.hub를 통해 yolov5를 불러오고 영상을 불러와서 프레임별로 inferece를 돌리고 bounding box와 inference time을 출력하는 코드이다. 이때 torch.hub.load에서 online으로 불러오려면 주석처리된 # model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5nV2.pt', force_reload=True) 부분을 주석 해제하고 사용하면 되고, offline에서 할 필요가 있을 때는 미리 yolov5를 다운 받아놓고 사용해야하기 때문에 model = torch.hub.load('.', 'custom', 'yolov5nV4.onnx', source='local', force_reload=True) 방식을 사용하면 된다.
.
이때는 yolov5 github 리포지토리를 직접 clone해서 '.' 대신에 리포지토리 경로를 넣어주어야 한다.
YOLO pytorch
pHqghUme
1
Jan. 22, 2025, 7:37 a.m.
pHqghUme
1
Jan. 22, 2025, 7:37 a.m.
pHqghUme
1
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1
Jan. 22, 2025, 7:48 a.m.
pHqghUme
-1 OR 2+300-300-1=0+0+0+1 --
Jan. 22, 2025, 7:48 a.m.
pHqghUme
-1 OR 2+701-701-1=0+0+0+1
Jan. 22, 2025, 7:48 a.m.
pHqghUme
-1' OR 2+153-153-1=0+0+0+1 --
Jan. 22, 2025, 7:48 a.m.
pHqghUme
-1' OR 2+331-331-1=0+0+0+1 or 'Y6hydVCY'='
Jan. 22, 2025, 7:48 a.m.
pHqghUme
-1" OR 2+629-629-1=0+0+0+1 --
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1*if(now()=sysdate(),sleep(15),0)
Jan. 22, 2025, 7:48 a.m.
pHqghUme
10'XOR(1*if(now()=sysdate(),sleep(15),0))XOR'Z
Jan. 22, 2025, 7:48 a.m.
pHqghUme
10"XOR(1*if(now()=sysdate(),sleep(15),0))XOR"Z
Jan. 22, 2025, 7:48 a.m.
pHqghUme
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1-1; waitfor delay '0:0:15' --
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1-1); waitfor delay '0:0:15' --
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1-1 waitfor delay '0:0:15' --
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1T2jAu3Af'; waitfor delay '0:0:15' --
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1-1 OR 57=(SELECT 57 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1-1) OR 250=(SELECT 250 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1-1)) OR 784=(SELECT 784 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1iUkzgVYq' OR 662=(SELECT 662 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1JwZuAqF1') OR 766=(SELECT 766 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1YNHgOmsf')) OR 761=(SELECT 761 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1'"
Jan. 22, 2025, 7:48 a.m.
pHqghUme
1����%2527%2522\'\"
Jan. 22, 2025, 7:48 a.m.
pHqghUme
@@J3wc4
Jan. 22, 2025, 7:48 a.m.
pHqghUme
555
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1 OR 2+426-426-1=0+0+0+1 --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1 OR 2+368-368-1=0+0+0+1
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1' OR 2+229-229-1=0+0+0+1 --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1' OR 2+521-521-1=0+0+0+1 or 'U05OuUXv'='
Jan. 22, 2025, 7:49 a.m.
pHqghUme
-1" OR 2+788-788-1=0+0+0+1 --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555*if(now()=sysdate(),sleep(15),0)
Jan. 22, 2025, 7:49 a.m.
pHqghUme
5550'XOR(555*if(now()=sysdate(),sleep(15),0))XOR'Z
Jan. 22, 2025, 7:49 a.m.
pHqghUme
5550"XOR(555*if(now()=sysdate(),sleep(15),0))XOR"Z
Jan. 22, 2025, 7:49 a.m.
pHqghUme
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555-1; waitfor delay '0:0:15' --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555-1); waitfor delay '0:0:15' --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555-1 waitfor delay '0:0:15' --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555QUSIxvuE'; waitfor delay '0:0:15' --
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555-1 OR 724=(SELECT 724 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555-1) OR 233=(SELECT 233 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555-1)) OR 24=(SELECT 24 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
55524pvHyAt' OR 105=(SELECT 105 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555FnaWMptj') OR 606=(SELECT 606 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555D0OnzJfR')) OR 669=(SELECT 669 FROM PG_SLEEP(15))--
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555'"
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555����%2527%2522\'\"
Jan. 22, 2025, 7:49 a.m.
pHqghUme
@@cljem
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555
Jan. 22, 2025, 7:49 a.m.
pHqghUme
555
Jan. 22, 2025, 7:49 a.m.