1. 파이썬으로 만드는 퍼셉트론(Perceptron)
Dec. 5, 2021, 11:48 p.m.
1. 퍼셉트론의 정의
퍼셉트론은 인공신경망의 아주 기초적인 종류중 하나로써, 1957년에 고안되었어요. 아주 간단한 형태의 선형 분류기입니다. 지도학습의 이진 분류에 사용할 수 있습니다.
이게 무슨 말이냐, 일단 선형 분류기라는 것은 어떤 데이터들을 하나의 직선으로 갈라서 구분한다는 것입니다. 예를 들어 아래와 같은 데이터가 있을 때...
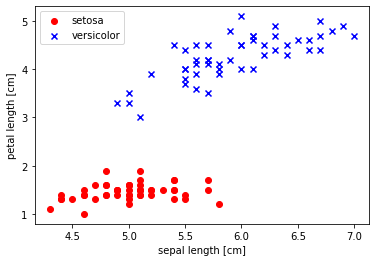
빨간색과 파란색, 두 가지로 구분하려면 어떻게 하면 될까요?
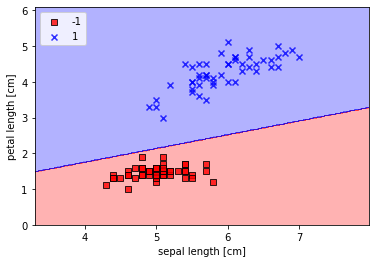
적절히 직선을 그어주면 되겠네요.
이렇듯 선형 분류기는 어떤 데이터를 선형(직선)을 그어 분류하게 됩니다. 그래서 이진 분류에 사용되는 것이죠.
이러한 선형 분류기를 학습시킨다는 것은 직선을 잘 그어서 데이터들을 두 가지로 완벽하게 분리할 수 있도록 만드는 것입니다.
그럼 이 분류 대상인 데이터들은 어떻게 구성될까요? 이 데이터 셋은 개의 수치값으로 구성된 가 있고 그것의 레이블인 이 있습니다. 예를 들자면 키가 180, 몸무게가 65인 사람은 BMI가 정상(1)이라는 데이터는 로 볼 수 있겠네요. 이런 수많은 데이터들이 있다고 했을때 선형 분류기는 키, 몸무게 데이터를 입력받고 그것이 정상(1)인지 비정상(0)인지를 분류하게 되는 것입니다.
그럼 이제 퍼셉트론에 대해서 알아볼까요?
기본적인 구조는 아래와 같습니다.
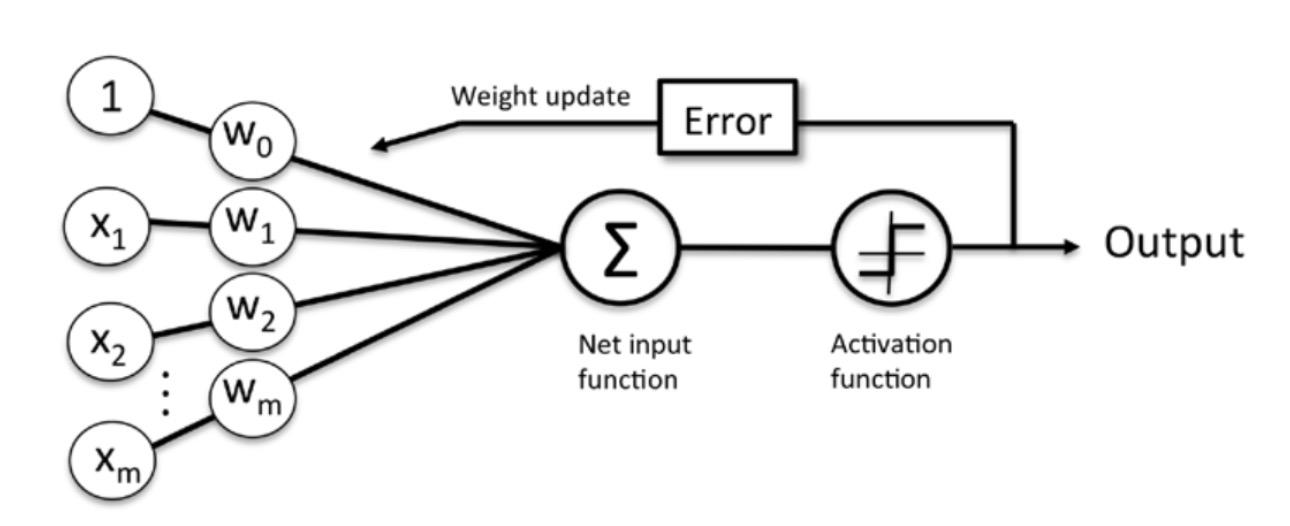
m개의 입력값과 m+1개의 가중치가 각각 곱해져 더해진다음 활성화 함수를 거쳐 출력이 나오는 형태입니다. 이때 가중치가 1개 더 많은이유는 bias, 즉 편향을 주기 위해서입니다. 여기서 활성화 함수는 계단함수를 사용합니다. 계단함수는 이렇게 생겼습니다!
수식으로 표현하면 아래와 같습니다.
이때의 f는 활성화 함수로써 계단 함수입니다.
더 자세히 수식으로 나타내보면 아래와 같습니다.
보시다시피 입력값 와 가중치 가 곱해지고 편향 가 더해지는 모습을 볼 수 있습니다. 이 계산의 결과값이 활성화 함수인 계단함수를 거쳐 값을 얻게 되는 것입니다.
이 퍼셉트론을 학습한다는 것은 결국 이 값이 실제 레이블 값인 값과 일치하도록 만드는 것입니다.
2. 퍼셉트론의 학습
퍼셉트론은 어떻게 학습 될까요?
퍼셉트론이 학습 된다는 것은 결국 예측한 레이블 값이 실제 레이블 값과 일치해야 된다는 뜻입니다. 다시 말해서 예측 레이블 값과 실제 레이블 값 사이의 오차가 없어야 한다는 뜻이죠. 즉, 퍼셉트론은 이 오차를 줄이는 방향으로 학습되며, 이 오차를 비용함수 혹은 목적함수라고도 부릅니다. 비용이 적을 수록 좋고, 이 함수의 값을 최소화 하는 것이 목적이니까요.
퍼셉트론 학습의 목표는 바로 이 오차를 최소화 하는 것! 하지만 이 오차라는 것은 양수가 될 수도 있고, 음수가 될 수도 있습니다. 오차에 절대값을 씌우기는 애매하죠. 그렇기 때문에 오차를 구한 후 제곱한 값(제곱 오차)을 사용합니다. 이것이 퍼셉트론의 비용합수이자 목적함수인 제곱 오차입니다.
i는 i번째 학습을 말합니다.
학습을 시작하면 제일 먼저 모든 가중치 w를 랜덤한 아주 작은 값으로 초기화합니다.
그 후 실제 클래스 레이블과 비교하며 아래와 같은 수식으로 가중치를 업데이트 하게 됩니다. 제곱 오차를 편미분 해서 제곱 오차를 줄이는 방향으로 가중치를 변화시킨다고 생각하세요.
여기서는 학습률을 의미합니다. 일반적으로 0에서 1사이의 실수를 사용합니다. 학습률이 클수록 빨리 학습이 되지만 너무 크게되면 오차가 수렴값을 지나쳐 발산할 경우가 있습니다. 그러므로 적절한 학습률을 정해주는 것이 좋습니다.
또한 는 실제 레이블 값입니다. 거기에서 출력값 를 빼주기 때문에 사실은 예측한 레이블 값과 실제 레이블 값의 오차를 구하는 것입니다. 여기에 학습률을 곱해 가중치에 더해주는 것이죠.
이것이 끝나면 다음 훈련 데이터를 집어 넣어 오차를 구하고 계산을 통해 가중치를 변화시킵니다. 모든 훈련 데이터를 대상으로 실시합니다. 모든 데이터를 집어넣으면 한번의 훈련이 끝나고 이 과정을 1 Epoch(에포크)라고 합니다.
이것을 반복하여 일정한 최대 에포크를 넘거나 완전히 이진 분류가 되는등 정해진 기준을 넘으면 훈련을 종료하면 됩니다. 아주 간단한 형태의 선형 분류기이기 때문에 정확히 이진 분류가 가능한 문제만 완벽하게 학습할 수 있답니다.
3. 파이썬 구현
이제 이것을 파이썬으로 직접 구현을 해보겠습니다. 관습적으로 파이썬의 머신러닝 클래스들은 fit, transform 그리고 predict 함수로 구성됩니다. 퍼셉트론은 transform은 필요하지 않고 fit을 통해 학습한 다음 predict로 클래스 레이블을 예측해보도록 하겠습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
class Perceptron(object):
def __init__(self, eta=0.01, n_iter=50, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self, X):
return np.dot(X,self.w_[1:]) + self.w_[0]
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, -1)
자세히 살펴보면 __init__() 함수를 통해 초기 설정값을 설정할 수 있습니다. eta가 학습률, n_iter가 반복할 횟수입니다.
그다음 fit() 함수로 학습을 진행하는데요, 레이블링 되어있는 학습 데이터를 X, 그리고 y로 넣어줍니다.
내부적으로 사용하는 net_input() 함수가 퍼셉트론의 계산을 나타냅니다. X와 w를 내적하고 편향값을 더해줍니다.
마지막으로 predict 함수로 계산된 값을 계단함수를 통과시켜 1 혹은 -1로 레이블을 예측합니다. 여기서 알 수 있듯이 학습할때 입력할 데이터는 레이블이 최대 두개만 가능하며 1 혹은 -1로 지정해주어야 합니다.
실제로 학습을 진행해보면 어떨까요?
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None)
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
X = df.iloc[0:100, [0,2]].values
ppn = Perceptron(eta=0.1, n_iter=10)
ppn.fit(X, y)
아주 유명한 머신러닝 학습 데이터인 붓꽃 분류 데이터를 UCI 홈페이지에서 가져와서 읽은 뒤, 텍스트로 라벨링 되어있는 데이터를 -1 혹은 1로 다시 라벨링 해줍니다. 그다음 퍼셉트론 객체를 생성해 학습해줍니다.
이제 ppn.predict([3.2, 5.1]) 과 같이 특정 값을 넣어서 클래스 레이블을 예측해볼 수 있습니다. 잘 학습이 되었다면 클래스 레이블이 1, 즉 versicolor 라는 것을 알 수 있습니다.
지금까지 머신러닝의 시초라고 볼 수 있는 퍼셉트론에 대해 알아보고 파이썬으로 구현해 보았습니다.
퍼셉트론