서포트 벡터 머신 (SVM) 사이킷런에서 사용하기
March 3, 2022, 11:52 p.m.
이번 포스트에서는 서포트 벡터 머신 (SVM)에 대해서 알아보도록 하겠습니다.
서포트 벡터 머신도 분류 알고리즘 중 하나입니다. 기본적인 아이디어는 클래스를 구분하는 결정 경계와 그 경계와 가장 가까운 샘플 사이의 거리를 최대로 하는 것을 목표로 학습을 진행하는 것입니다. 이 결정경계와 가장 가까운 샘플 사이의 거리를 마진 이라고 부릅니다.
아래의 그림이 SVM을 잘 설명하고 있네요!
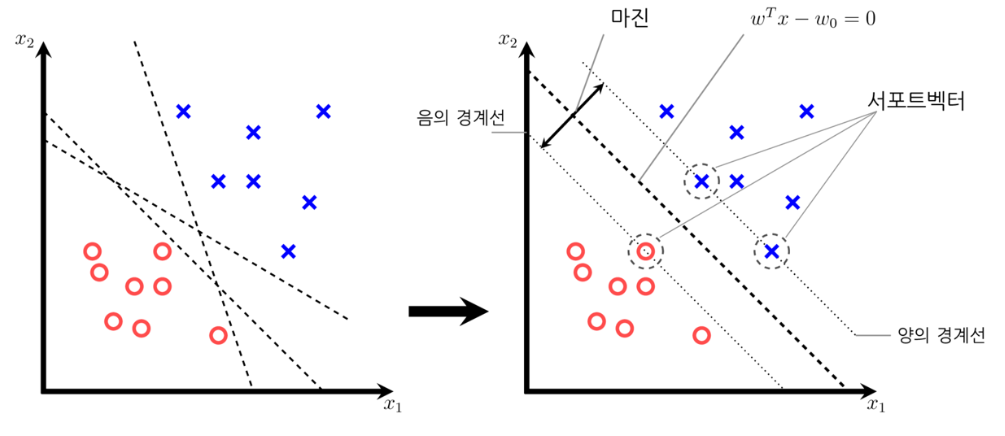
큰 마진을 가지는 결정경계가 생기면 학습 데이터 말고 일반적인 데이터를 넣었을 때도 오차가 별로 생기지 않습니다. 여유롭게 경계를 결정하기 때문이죠. 일반화 오차가 낮아진다고 볼 수 있겠습니다.
작은 마진을 가지는 결정경계가 생기면 클래스를 훨씬 타이트하게 구분하기 때문에 훈련시 정확도는 높을지 몰라도 훈련 데이터에 과대적합 되기 때문에 일반화 오차가 높아질 수 있습니다.
SVM에는 하나의 하이퍼파라미터 C가 있습니다. C값은 선형적으로 구분이 안되는 데이터에서 결정경계를 얼마나 여유롭게 결정할지에 대한 매개변수 입니다.
C 값이 작을 수록 소프트하게 분류하여 편향이 높아지게 됩니다. 즉, 테스트 셋에 대한 정확도는 줄어들지 몰라도 일반화 오차도 줄게 됩니다.
대신에 C 값이 클 수록 타이트하게 분류하여 분산이 높아지고 과대적합되어 테스트 셋에 대한 정확도가 증가하고 대신에 일반화 오류가 증가합니다.
그러므로 이 C 값을 적절하게 조절하여 편향과 과대적합의 사이에서 적절한 균형을 찾아야 합니다.
그럼 사이킷런에서 SVM을 사용해 보겠습니다. 훈련 데이터는 사이킷런에서 제공하는 iris(붗꽃) 데이터를 사용하였습니다.
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
iris = datasets.load_iris()
X = iris.data[:, [2,3]] //두개의 특성만 사용
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y) // stratify 옵션은 데이터를 나눌때 클래스별 비율을 동일하게 만든다.
svm = SVC(kernel='linear', C=1.0, random_state=1) // SVM 모델 생성
svm.fit(X_train, y_train) // 학습
데이터셋을 불러와서 두개의 특성(클래스)만 사용하도록 하여 테스트 셋과 학습 셋을 나누어 주었습니다.
그 다음 svm 모델을 생성하여 fit() 메서드로 학습을 시켜 주었습니다.
print(svm.predict(X_test)) // 테스트 셋 예측
print(svm.score(X_test, y_test)) // 정확도
predict() 메서드로 테스트 셋에 대한 예측 클래스 값을 받아볼 수 있습니다.
또한 score() 메서드로 테스트 셋의 정확도를 볼 수 있습니다.
[2 0 0 1 1 1 2 1 2 0 0 2 0 1 0 1 2 1 1 2 2 0 1 2 1 1 1 2 0 2 0 0 1 1 2 2 0
0 0 1 2 2 1 0 0]
0.9777777777777777
이번 포스트에서는 SVM에 대한 간단한 설명과 사이킷런에서 SVM 활용에 대해서 알아보았습니다. 테스트 셋의 정확도를 확인해 보면서 과대적합이 되어있는지, 아니면 편향이 되어있는지 판단하여 하이퍼파라미터 C 값을 변경해 가면서 학습을 하여 결과가 좋은 SVM 분류기를 만들어 보시기 바랍니다.
사이킷런 scikit-learn svm