사이킷런에서 결정 트리와 랜덤포레스트 사용하기
March 9, 2022, 11:35 p.m.
결정 트리는 대표적인 화이트박스 모델입니다. 화이트박스란 분류 과정을 설명할 수 있다는 뜻입니다. 신경망같은 모델은 내부에서 어떤 데이터에 가중치를 가지고 있는지, 어떤 특징을 잡아서 계산했는지 내부를 확인할 수 없고 결과만 나타냅니다.
그러나 결정트리같은 모델은 어떤 분류 기준을 가지고 해당 데이터를 레이블링 했는지를 알 수 있기 때문에 해당 데이터셋을 범주화하여 설명 할 수 있는 것입니다.
바로 사이킷런에서 결정트리를 사용하는 법을 알아보겠습니다.
1. 결정 트리 사용하기
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:, [2,3]]
y = iris.target
사이킷런에서 붖꽃 데이터셋을 불러왔습니다. 그 중에서 시각화를 위해 두개의 특성만 사용해 보겠습니다.
from sklearn.tree import DecisionTreeClassifier as DTC
tree = DTC(criterion='gini', max_depth=10, random_state=1)
tree.fit(X_train, y_train)
위와 같이 sklearn.tree에서 결정트리분류기를 불러올 수 있습니다. criterion은 불순도측정 방식을 말하는데 여기서는 gini불순도를 사용했습니다. max_depth는 트리의 최대 깊이를 말합니다. 최대 깊이를 무제한으로 하면 결정트리가 굉장히 상세해지면서 데이터에 과대적합되는 결과를 가져올 수 있기 때문에 항상 적절히 제한을 두어야 합니다.
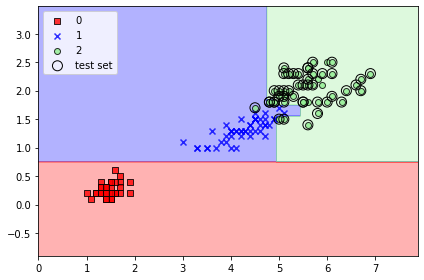
이렇게 결정트리가 데이터를 분류하는 모습을 볼 수 있네요. 이진 분류를 하기 때문에 결정 경계가 직선이고 그렇기 때문에 확실한 구분 기준이 생기고 데이터를 설명할 수 있게 됩니다.
2. 랜덤 포레스트 사용하기
랜덤 포레스트는 대표적인 앙상블 기법입니다. 여러개의 결정트리를 평균내어 결과를 나타내는 방법이라고 볼 수 있는데요, 트리 각각은 과대적합 되거나 분류를 완벽히는 못하게 되지만 랜덤 포레스트는 여러개의 결정 트리를 이용해 일반화 성능을 높입니다.
여기서 살짝만 더 설명하자면 각각의 트리는 전체 훈련 샘플에서 일부만 뽑고 특성도 일부만 뽑아 만들어진 부트스트랩 샘플로 훈련이 진행됩니다. 이는 과대적합을 막고 랜덤포레스트의 편향과 분산을 제어합니다.
앙상블 기법이다보니 결정 트리보다는 훈련 결과를 설명하기는 어렵겠지만 결정 트리보다 더욱 좋은 성능을 낼 수 있답니다.
사이킷런으로 사용해 보겠습니다.
from sklearn.ensemble import RandomForestClassifier as RFC
forest = RFC(criterion='gini', n_estimators=50, random_state=45, n_jobs=1)
forest.fit(X_train, y_train)
사이킷런 sklearn.ensemble 에서 모델을 불러와 사용해 보았는데요, 여기서는 n_estimators를 통해 사용할 트리의 개수를 지정합니다.
이번 포스트에서는 결정트리와 랜덤포레스트에 대해서 알아보았습니다. 간단하면서 빠르고, 성능이 괜찮아 유용히 쓰이는 모델이기 때문에 알아두면 좋을 것 같습니당.
사이킷런 scikit-learn 랜덤포레스트 결정트리