사이킷런에서 KNN 사용하기
March 10, 2022, 10:44 p.m.
KNN은 k-최근접 이웃 이라고도 불리는 아주 간단한 분류 알고리즘입니다. 로지스틱 회귀나 랜덤포레스트 같은 분류기는 훈련데이터를 통해 훈련 한 후 더이상 훈련 데이터가 필요하지 않지만 KNN은 다릅니다.
KNN 알고리즘은 아주 간단합니다.
- 숫자 k를 정합니다.
- 분류하려는 샘플에서 k개의 가장 가까운 이웃을 찾습니다.
- k개의 가장 가까운 이웃들 중에서 레이블을 다수결 투표하여 해당 샘플의 레이블을 할당합니다.
즉 KNN은 훈련데이터를 저장만 하고 있으면 분류하려는 샘플이 들어왔을 때 최근접 이웃을 찾고 다수결 투표하여 결과를 낼 수 있습니다.
그렇기 때문에 매우 간단하고 훈련에 필요한 시간이 거의 없다는 것이 장점이라고 볼 수 있겠습니다.
그러나 훈련 데이터의 양이 늘어나면 데이터를 모두 보유하고 있어야 하는 특성상 메모리 문제가 생기기도 하고 특성이 많아지게 되면 계산의 양도 굉장히 늘어나게 되고 과대적합의 우려가 커지는 문제도 있습니다.
보통은 가까운 이웃을 찾기 위해서 거리를 재야합니다. 거리를 재는 알고리즘은 다양한데 KNN에서는 보통 간단한 유클리디안 거리를 사용합니다. 혹은 minkowski 거리에서 p가 2일때를 유클리디안 거리로 사용합니다. 사이킷런에서는 metric 변수로 minkowski 거리에서 p 값을 조절하여 거리 알고리즘을 결정합니다.
p=1이면 Manhattan 거리, p=2면 유클리디안 거리입니다.
사이킷런으로 직접 KNN을 사용해 볼까요?
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:, [2,3]]
y = iris.target
print('label', np.unique(y))
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
사이킷런의 datasets에서 붖꽃 데이터를 받아왔습니다.
from sklearn.neighbors import KNeighborsClassifier as KNC
knn = KNC(n_neighbors=5, p=2, metric='minkowski')
knn.fit(X_train, y_train)
sklearn.neighbors에서 KNN을 가져왔습니다. K=5, p=2로 설정했으므로 5개의 최근접 이웃을 유클리디안 거리로 찾는 KNN 분류기가 되겠네요.
학습이 완료되면 아래와 같이 결정 경계가 생깁니다. 꽤나 잘 결정된 모습을 볼 수 있죠?
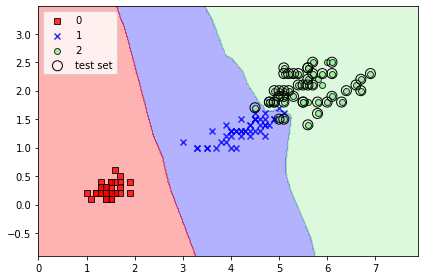
간단하게 KNN에 대해 알아보고 사이킷런 라이브러리에서 직접 사용해 보았습니다!
사이킷런 scikit-learn KNN