머신러닝 데이터 주성분 분석하기 : PCA와 KernelPCA
April 2, 2022, 11:48 p.m.
PCA는 특성사이의 상관관계를 분석해서 분산이 가장 큰 방향을 찾아 그것을 축으로 하는 새로운 좌표공간으로 데이터를 투영하는 방법으로 데이터의 특성을 추출하거나 차원을 줄이는데 사용합니다.
입력 데이터 간에 상관관계가 있더라도 PCA로 추출한 주성분은 서로 상관관계가 줄어들게 됩니다. 이를 통해 데이터의 새로운 특성을 추출하거나 벡터를 줄여 차원을 줄일 수 있게 되는 것입니다.
이때 중요한 사실은 PCA는 데이터의 스케일에 영향을 크게 받는다는 사실입니다. 그러므로 PCA를 적용하기 전에 표준화 전처리 등을 해서 데이터의 스케일을 일정하게 조정해서 모든 특성을 동일한 중요도로 다룰 수 있도록 해야합니다.
사이킷런을 이용해서 PCA를 적용해 보도록 하겠습니다.
import pandas as pd
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
from sklearn.model_selection import train_test_split
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=0)
X_train.shape
(124, 13)
데이터를 가져오고 테스트셋과 훈련셋을 분리했습니다. shape를 확인해 보니 124행에 13개의 특성을 가지고 있는 모습을 볼 수 있습니다.
표준화전처리를 해준 후 PCA를 적용해서 차원을 2차원으로 낮추어 보겠습니다.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc_train = sc.fit_transform(X_train)
표준화 전처리를 해주었습니다. 이제 모든 열의 평균이 0, 표준편차가 1로 바뀌었기 때문에 PCA가 동등하게 적용됩니다.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_train = pca.fit_transform(sc_train)
pca_train.shape
(124, 2)
차원이 2개로 줄은 모습을 볼 수 있네요!
클래스 별로 색을 다르게 해서 산점도로 그려보겠습니다.
from matplotlib import pyplot as plt
plt.scatter(pca_train[y_train==1,0], pca_train[y_train==1,1])
plt.scatter(pca_train[y_train==2,0], pca_train[y_train==2,1])
plt.scatter(pca_train[y_train==3,0], pca_train[y_train==3,1])
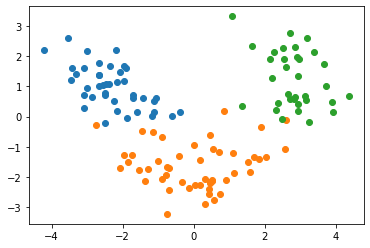
축소된 두 차원을 통해 데이터가 세 가지로 나누어지는 모습을 볼 수 있습니다. 차원 축소가 잘 진행되었네요.
만약 축소했는데도 선형적으로 잘 분리가 안되는 데이터를 만나면 어떻게 해야할까요?
이럴때는 KernelPCA를 사용할 수 있습니다. 일반 PCA는 데이터가 선형적으로 분석할 수 있다고 가정하였기 때문에 비선형 데이터를 완벽하게 추출할 수 없습니다. 또한 일반적인 대부분의 데이터는 비선형 데이터이죠. 그렇기 때문에 커널트릭을 사용해 PCA를 비선형적으로 적용할 수 있습니다. 커널 트릭이란 다양한 종류의 커널 함수를 이용해 데이터을 새로운 공간으로 투영하는 방법입니다.
같은 데이터로 KernelPCA를 사용해보겠습니다.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc_train = sc.fit_transform(train)
from sklearn.decomposition import KernelPCA
pca = KernelPCA(n_components=2, kernel="rbf", gamma=0.1)
pca_train = pca.fit_transform(sc_train)
잘 보시면 KernelPCA에 kernel인자를 rbf으로 넣어주었습니다. 이것은 커널 함수로 방사 기저 함수를 사용한다는 뜻입니다. 주로 이 함수를 사용합니다. 또한 gamma값을 0.01로 넣어 주었는데 이것은 하이퍼파라미터로써 직접 바꾸어 가면서 데이터가 잘 분석되는 값을 찾아야합니다. 저는 직접 찾아보니 0.01이 적당했네요
데이터 특성이 잘 추출되었는지 볼까요?
from matplotlib import pyplot as plt
plt.scatter(pca_train[y_train==1,0], pca_train[y_train==1,1])
plt.scatter(pca_train[y_train==2,0], pca_train[y_train==2,1])
plt.scatter(pca_train[y_train==3,0], pca_train[y_train==3,1])
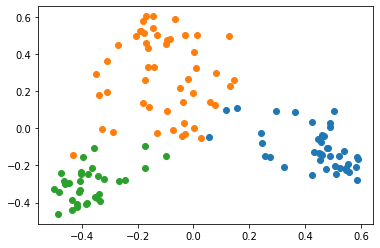
일반 PCA를 사용했을 때 보다 조금 더 잘 구분이 되는 모습을 볼 수 있습니다.
kernel PCA는 아래와 같은 비선형 데이터에 매우 좋은 성능을 냅니다.
from sklearn.decomposition import KernelPCA
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, random_state=123)
from matplotlib import pyplot as plt
plt.scatter(X[y==1,0], X[y==1,1])
plt.scatter(X[y==0,0], X[y==0,1])
사이킷런의 내장 데이터셋 생성 함수인 make_moon을 통해 반달 모양 데이터를 만들었습니다. 선형적으로 절대 분리가 불가능한 데이터죠?
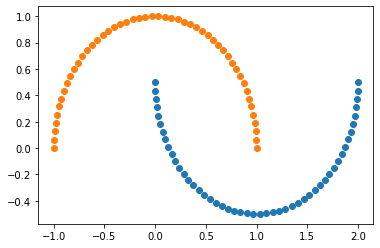
KernelPCA를 적용해 보겠습니다.
scikit_kpca = KernelPCA(n_components=2,kernel='rbf', gamma=15)
X_skernpca = scikit_kpca.fit_transform(X)
from matplotlib import pyplot as plt
plt.scatter(X_skernpca[y==1,0], X_skernpca[y==1,1])
plt.scatter(X_skernpca[y==0,0], X_skernpca[y==0,1])

이젠 완벽하게 선형으로 분리되겠네요. 그림을 보면 알 수 있듯이, x축만 가지고도 분리를 할 수 있습니다. 즉 차원도 1개 줄일 수 있겠네요.
이번 포스트에서는 이렇게 PCA와 kernelPCA에 대해서 알아보았습니다. 시각적으로 이해할 수 없는 다차원 데이터나 특성 간의 상관관계가 커서 새로운 특성을 추출하고 싶을 때는 PCA를 이용하면 됩니다.
PCA는 데이터의 레이블 정보 (y값)이 필요없이 데이터의 분포만으로 특성을 추출하는 비지도 기법이라는 사실을 잊지 마세요!
사이킷런 scikit-learn PCA