사이킷런 학습 곡선, 검증 곡선으로 모델의 과대적합, 과소적합 조사하기
April 4, 2022, 11:53 p.m.
모델이 높은 편향을 가지면 모델이 너무 단순해서 데이터에 과소적합 되었다는 것을 의미합니다. 이는 모델을 더 복잡하게 만들거나 훈련에 사용하는 데이터의 양을 늘려야 합니다.
모델이 높은 분산을 가지게 되면 모델이 너무 복잡해서 데이터에 과대적합 되었다는 것을 의미합니다. 이는 훈련에서의 정확도 보다 일반화 성능이 낮아짐을 의미합니다.
즉, 편향과 분산은 서로 Trade-Off 관계에 있습니다. 한가지를 얻으면 그만큼 나머지를 잃는 것이죠.(양자역학이 떠오르네요) 우리는 그러므로 모델이 편향과 분산의 적절한 균형을 이루어서 적절한 훈련 정확도와 일반화 성능을 얻어야 합니다.
학습 곡선과 검증 곡선은 모델의 과대적합이나 과소적합을 판별하기 위한 좋은 방법입니다.
1. 학습곡선
학습 곡선은 학습 데이터의 양을 늘려가면서 모델의 성능을 평가하여 그래프로 그리는 것입니다. 이를 통해 현재 데이터의 양이 적당한지, 더 모으면 모델의 성능이 증가할지 등에 대한 단서를 얻을 수 있죠.
사이킷런으로 그려보겠습니다!
사이킷런의 learning_curve를 통해 학습곡선 데이터를 얻을 수 있는데 이때 훈련 성능과 검증 성능을 따로 얻을 수 있습니다. 이때 검증은 k-fold로 진행되며 cv값을 통해 폴드의 개수를 정해줄 수 있습니다.
from sklearn.model_selection import learning_curve
from sklearn.linear_model import LogisticRegression
from matplotlib import pyplot as plt
import numpy as np
lr = LogisticRegression(solver='liblinear', multi_class='auto',C=100.0, random_state=78) //모델 선언
train_sizes, train_scores, test_scores = learning_curve(estimator=lr, X=X_train, y=y_train, train_sizes=np.linspace(0.1, 1.0, 10), cv=10) // 학습 곡선 얻기
train_mean = np.mean(train_scores, axis=1) //평균 구하기
train_std = np.std(train_scores, axis=1) // 표준편차 구하기
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(train_sizes, train_mean, color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(train_sizes, train_mean + train_std, train_mean - train_std, alpha=0.15, color='blue')
plt.plot(train_sizes, test_mean, color='green', linestyle='--', marker='s', markersize=5, label='validation accuracy')
plt.fill_between(train_sizes, test_mean + test_std, test_mean - test_std, alpha=0.15, color='green')
plt.grid()
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.tight_layout()
plt.show() // 그래프 그리기
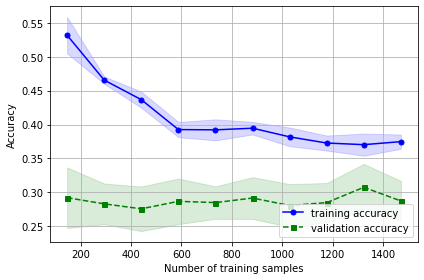
그래프가 잘 그려진 모습을 볼 수 있습니다. 학습에 사용된 데이터는 특성이 매우 많은 아주 복잡한 데이터 입니다. 그래프를 보면 알 수 있듯이, 처음에는 학습 성능이 검증 성능보다 높은 모습을 볼 수 있습니다. 모델이 데이터에 과대적합 되었다는 사실을 알 수 있습니다. 그러다가 학습에 사용된 데이터가 많아질 수록 학습 성능과 검증 성능이 비슷해 지는 것을 알 수 있습니다. 즉, 분산이 감소하였습니다.
그러나 아직 학습 성능이 검증 성능보다 높고 간격이 유지되는 것으로 보아 이 모델은 아직 학습이 충분히 진행되지 않았고, 편향이 크다는 것을 알 수 있습니다. 또한 이 간격이 학습 데이터의 수를 늘려도 유지된다는 것은 학습 데이터를 더 구해서 늘려도 크게 성능 향상이 기대되지 않는 다는 사실을 의미합니다.
즉, 데이터의 양이 부족해서 학습이 덜 진행 된 것 보다 모델 자체의 결함 때문에 학습이 더이상 진행되지 못한다는 사실에 비중을 더 둘 수 있겠습니다.
이렇듯 학습 곡선을 통해서 학습 데이터의 양에 따른 모델의 학습 여부를 알 수 있고, 이를 통해 데이터를 더 구할지, 모델을 개선시킬지 판단해 볼 수도 있겠습니다.
2. 검증 곡선
검증 곡선은 학습 곡선과 유사하지만 x축이 데이터의 양이 아닌 모델의 하이퍼 파라미터입니다. 즉, 하이퍼파라미터에 따른 과대, 과소 적합 여부를 판단할 수 있죠.
사이킷런으로 그려 보도록 하겠습니다.
from sklearn.model_selection import validation_curve
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]
train_scores, test_scores = validation_curve(estimator=lr, X=X_train, y=y_train, param_name='C', param_range=param_range, cv=10)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(param_range, train_mean, color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(param_range, train_mean + train_std, train_mean - train_std, alpha=0.15, color='blue')
plt.plot(param_range, test_mean, color='green', linestyle='--', marker='s', markersize=5, label='validation accuracy')
plt.fill_between(param_range, test_mean + test_std, test_mean - test_std, alpha=0.15, color='green')
plt.grid()
plt.xscale('log')
plt.legend(loc='lower right')
plt.xlabel('Param C')
plt.ylabel('Accuracy')
plt.tight_layout()
plt.show()
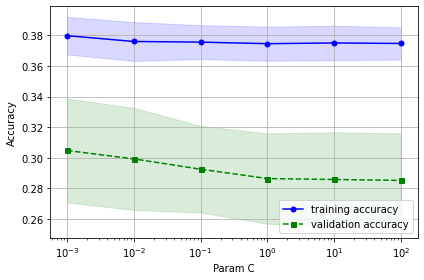
C값에 따른 훈련 성능과 검증 성능을 볼 수 있네요. 전체적으로 검증 성능이 낮기 때문에 과소 적합되었다고 볼 수 있네요.
이렇듯 검증 곡선을 통해서 모델의 특정 매개변수를 적절한 값으로 조절할 수 있습니다.
사이킷런 scikit-learn 학습 곡선 검증 곡선