강화학습: 파이썬으로 구현하는 큐러닝, Q Learning
May 7, 2022, 11:37 p.m.
1. 큐러닝(Q Learning)이란?
22.06.08 save, load 기능 업데이트 큐러닝은 오프폴리시 시간차 제어를 통한 강화학습 알고리즘입니다. 이게 뭔소리냐 싶은데 이전에 SARSA 알고리즘을 알아보았는데요 강화학습: 파이썬으로 구현하는 SARSA, 살사 알고리즘. 살사 알고리즘은 온폴리시 시간차 제어입니다.
온폴리시, 오프폴리시가 무슨 뜻일까요? 바로 학습에 있어서 정책에 영향을 받는지 여부를 말합니다. SARSA와 같은 온폴리시 알고리즘은 업데이트 과정에서 에이전트의 다음상태와 다음상태의 행동 샘플이 필요한데 이것은 에이전트의 현재 정책에 영향을 받습니다. 즉, 에이전트가 행동하는대로 학습하게 되는 것입니다.
그러므로 업데이트 하는 과정에서 에이전트가 탐험을 하게 된다면 이를 그대로 학습하게 되고 잘못된 정책으로 흘러가게 되는 것입니다.
이를 방지하고자 오프폴리시 알고리즘인 큐러닝이 만들어졌다고 합니다. 큐러닝은 어떻게 정책의 영향을 받지 않게 되었을까요?
SARSA는 S A R S' A' 총 5개의 샘플을 통해 학습을 하기 때문에 A'를 가져오는 과정에서 정책의 영향을 받습니다. 그러나 큐러닝은 S A R S' 4개의 샘플만 필요합니다. 그러면 A'를 무엇으로 대체하였을까요?
큐러닝은 A'를 S'에서 가장 큰 큐함수로 사용합니다. 즉 에이전트가 실제로 다음상태 S'에서 어떤 행동을 할 지와는 상관없이 S'에서 가장 큰 큐함수를 사용하기 때문에 정책의 영향을 받지 않게 됩니다.
큐러닝에서의 큐함수 업데이트 식은 아래와 같습니다.
벨만 최적 방정식과 유사하게 생겼습니다.
이처럼 큐러닝은 실제로 하는 행동과 학습시 사용하는 행동이 다릅니다. 살사처럼 갇히는 일이 일어나지 않게 되죠.
2. 파이썬으로 구현하기
파이썬으로 큐러닝 에이전트를 구현해 볼까요? 위키북스의 파이썬과 케라스로 배우는 강화학습 책을 참고했습니다.
import numpy as np
import pandas as pd
import random
from collections import defaultdict
class QLearning:
def __init__(self, actions):
self.ACTIONS = np.array(actions)
self.step_size = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1
self.q_table = defaultdict(lambda:[0.0 for _ in range(len(actions))])
def get_action(self, state):
if np.random.rand() < self.epsilon:
action = np.random.choice(self.ACTIONS)
else:
q_list = self.q_table[str(state)]
action = self.ACTIONS[np.random.choice(np.argwhere(q_list == np.amax(q_list)).flatten().tolist())]
return action
def save(self, root):
df = pd.DataFrame([[state, self.q_table[state]] for state in self.q_table.keys()], columns=['states', 'q_list'])
df.to_csv(root)
def load(self, root):
def str_to_list(s):
s = s.split('[')
s = s[1].split(']')
s = s[0].split(', ')
for i in range(len(s)):
s[i] = float(s[i])
return s
self.q_table = defaultdict(lambda:[0.0 for _ in range(len(self.Actions))])
df = pd.read_csv(root)
for idx in df.index:
self.q_table[df['states'][idx]] = str_to_list(df['q_list'][idx])
def learn(self, state, action, reward, next_state):
state, next_state = str(state), str(next_state)
current_q = self.q_table[state][np.argwhere(self.ACTIONS==action)[0][0]]
next_state_q = max(self.q_table[next_state])
td = reward + self.discount_factor * next_state_q - current_q
new_q = current_q + self.step_size * td
self.q_table[state][np.argwhere(self.ACTIONS==action)[0][0]] = new_q
살사 에이전트와 똑같이 3가지 부분으로 나누어집니다.
1) 에이전트 초기화 하기
class QLearning:
def __init__(self, actions):
self.ACTIONS = np.array(actions)
self.step_size = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1
self.q_table = defaultdict(lambda:[0.0 for _ in range(len(actions))])
초기화할때 매개변수로 에이전트가 행동할 행동 리스트를 받습니다. [1, 2, 3, 4]와 같이 넣어주면 됩니다.
또한 스텝사이즈 (위에 수식에서 역할), 할인율, 탐험율 등을 지정할 수 있습니다.
2) 행동 가져오기 get_action(state)
def get_action(self, state):
if np.random.rand() < self.epsilon:
action = np.random.choice(self.ACTIONS)
else:
q_list = self.q_table[str(state)]
action = self.ACTIONS[np.random.choice(np.argwhere(q_list == np.amax(q_list)).flatten().tolist())]
return action
상태정보를 넣으면 행동을 반환합니다. 살사와 동일하게 - 탐욕 정책을 적용하였습니다.
3) 학습하기
def learn(self, state, action, reward, next_state):
state, next_state = str(state), str(next_state)
current_q = self.q_table[state][np.argwhere(self.ACTIONS==action)[0][0]]
next_state_q = max(self.q_table[next_state])
td = reward + self.discount_factor * next_state_q - current_q
new_q = current_q + self.step_size * td
self.q_table[state][np.argwhere(self.ACTIONS==action)[0][0]] = new_q
큐러닝의 큐함수 업데이트 식을 통해 큐함수를 업데이트 합니다. S A R S' 샘플을 받아 상태 S'에서의 최대 큐함수를 구하고 스텝사이즈 만큼 업데이트 합니다.
4) 저장하기
def save(self, root):
df = pd.DataFrame([[state, self.q_table[state]] for state in self.q_table.keys()], columns=['states', 'q_list'])
df.to_csv(root)
이렇게 해서 만들어진 큐함수 테이블을 csv파일 형태로 저장하는 기능입니다. 나중에 불러오기로 다시 불러올 수도 있습니다.
5) 불러오기
def load(self, root):
def str_to_list(s):
s = s.split('[')
s = s[1].split(']')
s = s[0].split(', ')
for i in range(len(s)):
s[i] = float(s[i])
return s
self.q_table = defaultdict(lambda:[0.0 for _ in range(len(self.Actions))])
df = pd.read_csv(root)
for idx in df.index:
self.q_table[df['states'][idx]] = str_to_list(df['q_list'][idx])
앞서 저장된 csv 파일을 읽어서 다시 딕셔너리 형태로 변환하여 큐함수 테이블에 저장합니다.
3. 그리드월드에 적용해보기
그럼 이제 큐러닝 에이전트가 잘 작동하는지 그리드월드 환경에 적용해보겠습니다. 그리드월드 환경은 제가 직접 작성한 환경입니다. 사용방법과 자세한 것은 저의 블로그 글과 깃허브를 참고하세요 블로그, 깃허브
먼저 환경을 세팅해 주겠습니다.
env = GridWorld(5, 5, state_method="absolute", goal_included_in_state=False)
env.add_obstacles(1, 1, 0, include_state=False)
env.add_obstacles(0, 3, 0, include_state=False)
env.add_obstacles(3, 0, 0, include_state=False)
env.add_obstacles(4, 2, 0, include_state=False)
env.add_obstacles(2, 4, 0, include_state=False)
env.show([0, 0], 0, 0)
5X5 그리드 월드 환경에 (1, 1) , (0, 3), (3, 0), (4, 2), (2, 4)에 장애물이 정지해 있는 환경입니다. 도달해야하는 목표는 (4, 4)에 위치해 있습니다. 제가 만든 그리드월드를 사용해서 구성하면 아래와 같습니다. goal_included_in_state=False와 include_state=False를 통해 상태 정보에는 오로지 에이전트의 위치만 담기도록 합니다.
또한 현재 보상은 기본값으로 장애물에 닿았을 때 -1, 벽으로 가는 행동을 했을 때 -1, 목표에 도달했을 때 1, 그리고 매 스텝마다 -0.1입니다.
아래와 같이 그리드월드 환경이 구성되었습니다.
state:[0, 0], reward:0, action:O
------------
|A # # O # |
|# O # # # |
|# # # # O |
|O # # # # |
|# # O # G |
------------
그다음 에이전트를 생성하고 학습을 진행해 보겠습니다.
agent = QLearning([1, 2, 3, 4])
episodes = []
scores = []
for E in range(1000):
state = env.reset()
done = False
score = 0
while not done:
action = agent.get_action(state)
next_state, reward, done = env.step(action, show=False)
next_action = agent.get_action(next_state)
agent.learn(state, action, reward, next_state)
score += reward
state = next_state
print(f"episode {E} - score {score}")
scores.append(score)
episodes.append(E)
행동 목록으로 [1, 2, 3, 4]를 넣어주었습니다. 각각 그리드월드 상에서 상, 하, 좌, 우로 이동하는 행동입니다.
그 다음으로 각 에피소드당 스코어를 담을 빈 리스트를 만들어 주었습니다. 나중에 스코어 그래프를 그릴 때 사용합니다.
for문으로 총 1000개의 에피소드를 진행합니다.
먼저 환경의 reset()함수를 이용해 환경을 초기화하고 최초 상태를 받습니다. 그리고 에피소드 종료 여부를 저장할 변수 done을 만들어 줍니다.
while문을 사용해 한 스텝씩 에피소드가 끝날때까지 반복합니다. 먼저 에이전트에게 상태를 넘겨주고 행동을 받아옵니다. 그리고 env.step()을 이용해 그 행동을 하고, 다음 상태 행동과 보상, 완료여부를 받습니다. 이를 기반으로 에이전트는 learn()을 통해 학습합니다. 점수를 더해주고 현재 상태를 다음 상태로 만들어주면서 한 스텝을 마무리합니다.
에피소드가 완료되면 누적된 점수를 리스트에 추가해줍니다.
위의 코드를 실행해보면 아래처럼 학습이 진행되는 모습을 볼 수 있을 겁니다.
episode 0 - score -36.100000000000094
episode 1 - score 1.1102230246251565e-16
episode 2 - score -6.299999999999995
episode 3 - score -8.599999999999996
episode 4 - score -1.600000000000001
episode 5 - score -13.699999999999973
episode 6 - score -10.299999999999983
episode 7 - score -8.199999999999987
episode 8 - score -12.199999999999976
episode 9 - score -9.09999999999999
episode 10 - score 1.1102230246251565e-16
episode 11 - score -21.600000000000048
episode 12 - score -3.0000000000000018
episode 13 - score -4.899999999999999
episode 14 - score -6.399999999999993
episode 15 - score -1.9000000000000004
episode 16 - score -5.4999999999999964
점수가 점차 증가하는 것이 보이시나요? 그래프를 그려 학습 진척도를 보겠습니다.
from matplotlib import pyplot as plt
plt.plot(episodes, scores)
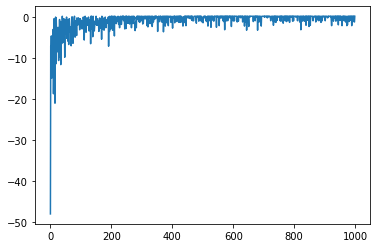
처음에는 점수가 낮다가 점차 증가하면서 수렴하는 모습을 볼 수 있습니다. 학습이 잘 되었네요.
그럼 이제 1000 에피소드동안 학습한 큐러닝 에이전트가 그리드월드를 움직이는 모습을 직접 볼까요?
state = env.reset()
done = False
score = 0
while not done:
action = agent.get_action(state)
next_state, reward, done = env.step(action, show=True)
next_action = agent.get_action(next_state)
score += reward
state = next_state
env.step()에서 show=True로 하므로써 프롬프트에 그리드월드가 출력됩니다.
state:[1, 0], reward:-0.1, action:>
------------
|# A # O # |
|# O # # # |
|# # # # O |
|O # # # # |
|# # O # G |
------------
state:[1, 0], reward:-1.1, action:^
------------
|# A # O # |
|# O # # # |
|# # # # O |
|O # # # # |
|# # O # G |
------------
state:[2, 0], reward:-0.1, action:>
------------
|# # A O # |
|# O # # # |
|# # # # O |
|O # # # # |
|# # O # G |
------------
state:[2, 1], reward:-0.1, action:v
------------
|# # # O # |
|# O A # # |
|# # # # O |
|O # # # # |
|# # O # G |
------------
state:[2, 2], reward:-0.1, action:v
------------
|# # # O # |
|# O # # # |
|# # A # O |
|O # # # # |
|# # O # G |
------------
state:[2, 3], reward:-0.1, action:v
------------
|# # # O # |
|# O # # # |
|# # # # O |
|O # A # # |
|# # O # G |
------------
state:[3, 3], reward:-0.1, action:>
------------
|# # # O # |
|# O # # # |
|# # # # O |
|O # # A # |
|# # O # G |
------------
state:[4, 3], reward:-0.1, action:>
------------
|# # # O # |
|# O # # # |
|# # # # O |
|O # # # A |
|# # O # G
------------
state:[4, 4], reward:0.9, action:v
------------
|# # # O # |
|# O # # # |
|# # # # O |
|O # # # # |
|# # O # A |
------------
잘 움직이나요? 에이전트가 학습이 잘 되었네요. 이번 포스트에서는 많은 강화학습 알고리즘의 기초가 된 큐러닝 알고리즘에 대해서 알아보았습니다.
큐러닝 에이전트 코드는 제 깃허브 Python_RL_Agents QLearning.py에서 확인할 수 있습니다.
강화학습 큐함수 그리드월드 큐러닝