강화학습 : 파이썬으로 구현하는 DEEP SARSA, 딥살사
May 13, 2022, 11:54 p.m.
이번에는 딥러닝 신경망을 이용한 강화학습, 딥살사에 대해서 알아보겠습니다. 이전에 살사 알고리즘에 대해서 알아보았는데요, 여기서 달라진 것은 테이블을 이용해서 큐함수를 모두 저장하는 것이 아니라 신경망을 통해 큐함수를 근사하는 차이점이 있습니다.
신경망을 사용하면 좋은 점이 무엇일까요? 그리드월드와 같은 환경은 사실 상태의 수가 한정되어 있습니다. 그렇기 때문에 일일이 테이블에 각 상태에 해당하는 큐함수를 저장할 수 있었죠. 그러나 좀 더 복잡한 환경에서 강화학습을 진행할 경우 문제가 생깁니다. 상태의 수가 너무 많게 되고 특히 연속적인 환경에서 진행하게 되는경우 소수점이 들어가기도 합니다. 이에대한 모든 상태를 각각 저장할 수 없기 때문에 우리는 근사할 필요가 생기게 됩니다.
여기서 신경망이 필요하게 되고 강화학습 알고리즘은 신경망을 이용하게 되면서 딥러닝으로 불리우게 됩니다. 딥살사는 말 그대로 신경망을 사용한 살사 알고리즘 입니다. 더 자세히 알아보겠습니다.
1. 딥 살사란?
살사 알고리즘에 대한 설명은 제 포스트 강화학습: 파이썬으로 구현하는 SARSA, 살사 알고리즘를 참고하세요. 딥 살사는 여기서 신경망을 대입했다는 점이 다른데요, 어떻게 신경망을 도입했을까요? 살사 알고리즘에서 큐함수를 업데이트 하는 식은 아래와 같았습니다.
이 식은 큐함수 업데이트의 목표가 되는 값 현재 값 와 업데이트 하는 정도 로 구성됩니다. 신경망에서는 목표가 되는 값을 정답, 현재 값을 예측이라고 해석합니다. 그리고 예측 값이 정답 값이 되도록 학습을 진행하게 되는 것이죠. 이때 학습률이 의 역할을 하게 됩니다.
신경망을 학습시키기 위해서는 오차함수가 필요합니다. 정답과 예측의 오차를 정의하는 함수이죠. 신경망 학습의 목적은 이 오차함수의 값을 최소로 하는 것입니다. 오차함수는 어떤 상황에서 어떤 학습을 진행하는지에 따라 굉장히 다양하게 구성할 수 있고 이 오차함수에 따라 학습이 어떻게 진행될지도 정해집니다.
딥살사에서는 MSE를 사용합니다. MSE는 제곱오차합으로써 단순히 정답과 예측의 차이를 제곱해서 더합니다. 식으로 나타내면 아래와 같겠네요.
정리를 해보자면 딥살사는 살사알고리즘과 학습과정은 동일하지만 큐함수를 신경망을 통해 근사한다는 점이 다르고 큐함수의 정답과 예측을 MSE에 넣어서 신경망의 가중치를 업데이트함으로써 학습을 진행합니다.
여기에 초반에는 탐험을 하면서 다양한 상태를 경험할 수 있도록 -탐험 정책을 사용합니다. 처음에는 값을 1로 해서 탐험을 많이 하다가 점점 이 값을 줄여가면서 수렴하도록 하겠습니다.
2. 파이썬으로 구현하기
딥살사를 파이썬으로 구현하는 과정에 있어서 가장 중요한 것은 역시 신경망을 구현하고 학습하는 과정을 만드는 것입니다. 저는 텐서플로와 케라스를 사용했습니다. 파이썬 환경에서 너무 좋은 인터페이스를 제공해 주기 때문입니다. 먼저 코드 전문을 볼까요?
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
import numpy as np
import random
class NN(tf.keras.Model):
def __init__(self, action_size):
super(NN, self).__init__()
self.fc1 = Dense(30, activation='relu')
self.fc2 = Dense(30, activation='relu')
self.fc_out = Dense(action_size)
def call(self, x):
x = self.fc1(x)
x = self.fc2(x)
q = self.fc_out(x)
return q
class DEEP_SARSA:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.discount = 0.99
self.epsilon = 1
self.learning_rate = 0.001
self.epsilon_decay = 0.99999
self.epsilon_min = 0.01
self.model = NN(self.action_size)
self.optimizer = Adam(learning_rate=self.learning_rate)
def get_action(self, state):
if np.random.rand() < self.epsilon:
return random.randrange(self.action_size)
else:
q = self.model(state)[0]
return np.argmax(q)
def learn(self, state, action, reward, next_state, next_action, done):
if self.epsilon > self.epsilon_min:
self.epsilon = self.epsilon * self.epsilon_decay
model_params = self.model.trainable_variables
with tf.GradientTape() as tape:
tape.watch(model_params)
predict = self.model(state)[0]
predict = tf.reduce_sum(tf.one_hot([action], self.action_size) * predict, axis=1)
next_q = self.model(next_state)[0][next_action]
target = reward + (1-done) * self.discount * next_q
loss = tf.reduce_mean(tf.square(target - predict))
grads = tape.gradient(loss, model_params)
self.optimizer.apply_gradients(zip(grads, model_params))
총 4가지 정도로 나누어볼 수 있겠네요. 신경망을 선언하는 부분, 에이전트 초기화, 에이전트의 행동 가져오기, 그리고 에이전트의 학습하는 부분입니다.
먼저 신경망을 구성하는 부분을 살펴보겠습니다.
class NN(tf.keras.Model):
def __init__(self, action_size):
super(NN, self).__init__()
self.fc1 = Dense(30, activation='relu')
self.fc2 = Dense(30, activation='relu')
self.fc_out = Dense(action_size)
def call(self, x):
x = self.fc1(x)
x = self.fc2(x)
q = self.fc_out(x)
return q
사실 케라스의 시퀀셜을 사용해도 되지 않나 싶지만 직접 keras.Model를 상속받는 모델을 만들었습니다. 초기화 할때 Dense라는 신경망을 2층을 만들고 마지막으로 행동의 크기를 가지는 출력층 하나를 만듭니다. 활성화 함수는 relu로 해주었습니다.
Model을 상속받기 때문에 call()이라는 함수를 선언해 주어야 합니다. 이것은 나중에 모델에 값을 넣을 때 사용됩니다. 딥살사에서 사용되는 신경망은 단순히 순차적인 신경망이기 때문에 입력으로 x가 들어오면 각각의 신경층을 지나 출력을 반환하게 만들어 주었습니다.
그럼 이제 에이전트를 만들겠습니다. 먼저 초기화 하는 부분입니다.
class DEEP_SARSA:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.discount = 0.99
self.epsilon = 1
self.learning_rate = 0.001
self.epsilon_decay = 0.99999
self.epsilon_min = 0.01
self.model = NN(self.action_size)
self.optimizer = Adam(learning_rate=self.learning_rate)
초기화 할 때 상태의 크기와 행동의 크기를 입력받습니다. 학습률과 할인율도 선언했구요. -탐험 정책을 구현하기 위해 탐험율, 학습율을 선언했고 매 행동마다 탐험율을 감소시키기 위해서 탐험율의 감소율도 정해줍니다. 그리고 탐험율이 너무 작아지지 않도록 탐험율의 최솟값도 정해주었습니다.
그리고 이전에 만들어준 신경망 모델을 self.model에 넣어주었고 self.optimizer에 Adam 객체를 넣어주었습니다. optimizer는 신경망의 가중치를 업데이트 해주는 도구라고 볼 수 있는데요, 여러 종류의 옵티마이저가 있지만 여기서는 Adam을 사용해 주겠습니다. learning_rate는 가중치의 업데이트 정도를 말하는데 이전에 정의한 학습률을 넣어줍니다. 이렇게 딥살사 에이전트의 초기화를 완료했습니다.
에이전트의 행동을 가져오는 부분을 살펴보겠습니다.
def get_action(self, state):
if np.random.rand() < self.epsilon:
return random.randrange(self.action_size)
else:
q = self.model(state)[0]
return np.argmax(q)
간단하죠? -탐험 정책에 따라 0에서 1사이의 난수를 뽑아 그 수가 (\epsilon) 보다 작으면 할 수 있는 행동중에서 무작위로 행동합니다. 그렇지 않으면 상태값을 신경망에 넣어 그 출력 벡터를 가져와 np.argmax()로 최대 인덱스를 뽑아 반환합니다.
마지막으로 학습하는 부분 살펴보겠습니다.
def learn(self, state, action, reward, next_state, next_action, done):
if self.epsilon > self.epsilon_min:
self.epsilon = self.epsilon * self.epsilon_decay
model_params = self.model.trainable_variables
with tf.GradientTape() as tape:
tape.watch(model_params)
predict = self.model(state)[0]
predict = tf.reduce_sum(tf.one_hot([action], self.action_size) * predict, axis=1)
next_q = self.model(next_state)[0][next_action]
target = reward + (1-done) * self.discount * next_q
loss = tf.reduce_mean(tf.square(target - predict))
grads = tape.gradient(loss, model_params)
self.optimizer.apply_gradients(zip(grads, model_params))
살사 학습에 사용되는 S A R S' A' 총 5개의 샘플과 done이라는 에피소드가 끝났는지 확인하는 변수까지 6개의 매개변수를 받습니다. 맨 처음으로 (\epsilon)를 감소시킵니다. 그리고 학습할 신경망의 파라미터를 가져옵니다. 그 다음에 이제 오차함수를 구해서 역전파 학습을 해야하는데 이때 미분을 하기 위해서는 오차함수 결과값만 필요한 것이 아니라 구하는 과정도 알아야 합니다.
이때 사용되는 것이 텐서플로의 GradientTape입니다. with키워드로 GradientTape()을 사용하는 컨텍스트 안에서는 텐서플로상에서 계산되는 과정이 모두 tape에 기록됩니다. 이것을 오차함수를 다 계산한 다음에 tape.gradient()로 그래디언트를 구해 가중치를 학습할 수 있는 것이죠. 컨텍스트 처음에 tape.watch()를 이용해서 신경망의 가중치들이 계산되는 과정을 기록하도록 하였습니다.
오차함수는 먼저 모델의 예측값(현재 큐함수)를 받아온 뒤에 tf.reduce_sum()을 이용해서 텐서플로에 값을 기록시킵니다. 큐함수를 업데이트 시킬 정답값(다음상태 큐함수)를 받아옵니다. 그리고 업데이트 목표 값(target)을 계산하고 마지막으로 tf.reduce_mean()을 이요해서 오차함수인 MSE를 게산합니다. 그리고 target값을 구하는 과정에서만약 에피소드가 끝날 경우 다음 상태가 없기 때문에 done 변수를 이용해 보상값만 고려하도록 했습니다.
오차함수를 구하는 과정을 기록했다면 tape.gradient()를 이용해 미분합니다. loss를 model_params에 대해서 미분했다고 생각하면 됩니다. 마지막으로 optimizer.apply_gradients()를 통해 가중치를 업데이트 하면 됩니다.
파이썬으로 다 구현해 보았으니 실제로 적용해 봅시다.
3. 에이전트 그리드월드에 적용해보기
딥살사 에이전트가 그리드월드를 돌아다니도록 해보겠습니다. 그리드월드 코드는 강화학습: 파이썬으로 구현한 프롬프트 그리드월드를 확인하세요.
코드 전문입니다.
env = GridWorld(5, 5, state_method="absolute")
env.add_obstacles(0, 1, 4)
env.add_obstacles(1, 2, 4)
env.add_obstacles(2, 3, 4)
state_size = env.state_size
action_size = env.action_size
agent = DEEP_SARSA(state_size, action_size)
scores = []
episodes = []
EPISODES = 10000
for e in range(EPISODES):
done = False
score = 0
state = env.reset()
state = np.reshape(state, [1, state_size])
while not done:
action = agent.get_action(state)
next_state, reward, done = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
next_action = agent.get_action(next_state)
agent.learn(state, action, reward, next_state, next_action, done)
score += reward
state = next_state
scores.append(score)
episodes.append(e)
print(f"epi-{e}:score-{score}:epsilon{agent.epsilon}")
먼저 환경과 에이전트를 초기화 하는 부분을 살펴보겠습니다.
env = GridWorld(5, 5, state_method="absolute")
env.add_obstacles(0, 1, 4)
env.add_obstacles(1, 2, 4)
env.add_obstacles(2, 3, 4)
state_size = env.state_size
action_size = env.action_size
agent = DEEP_SARSA(state_size, action_size)
5X5의 그리드월드를 생성했습니다. 기본적으로 [0, 0]에서 에이전트가 시작하고 목적지는 [4, 4]입니다. 각각 [0, 1], [1, 2], [2, 3]에 오른쪽으로 이동중인 장애물 3개를 생성했습니다. 이 장애물들은 벽에 부딪히면 튕깁니다. 그리고 상태의 크기와 행동의 크기를 환경으로부터 받아왔습니다. 상태는 [에이전트의 좌표(x, y), 목적지까지의 상대좌표 (x, y), 각 장애물들의 상대좌표와 장애물의 속도(x, y, v)]로 구성됩니다. 장애무리 3개이므로 2+2+3*3해서 상태의 크기는 총 13입니다. 행동의 크기는 [0, 1, 2, 3, 4]로 총 5이며 각각 정지, 상, 하, 좌, 우를 의미합니다.
그리고 딥살사 에이전트 객체를 선언합니다.
이제 에피소드를 진행하면서 학습하는 구간입니다.
scores = []
episodes = []
EPISODES = 10000
for e in range(EPISODES):
done = False
score = 0
state = env.reset()
state = np.reshape(state, [1, state_size])
while not done:
action = agent.get_action(state)
next_state, reward, done = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
next_action = agent.get_action(next_state)
agent.learn(state, action, reward, next_state, next_action, done)
score += reward
state = next_state
scores.append(score)
episodes.append(e)
print(f"epi-{e}:score-{score}:epsilon{agent.epsilon}")
먼저 학습이 완료된 후에 학습 그래프를 그릴 수 있도록 에피소드마다 점수를 저장할 리스트를 만들었습니다. 총 10000번의 에피소드를 진행할건데요, for 문을 이용해 반복할 것입니다.
for문이 시작되면 에피소드의 종료여부를 담는 done 변수, 점수를 저장할 score변수를 만듭니다. 그리고 env.reset()를 통해 환경을 처음상태로 만들고 그때의 상태를 받아옵니다. 그리고 신경망에 넣어줄때는 미니배치 형태로 넣어주기 때문에 np.reshape로 차원을 하나 늘려줍니다.
그리고 while문을 통해 에피소드가 끝날 때 까지 아래의 과정(한 스텝)을 반복하게 됩니다.
먼저 에이전트로부터 행동을 받아옵니다. 그리고 환경에 행동을 넣어 한 스텝을 움직입니다. 그리고 다음 상태와 보상, 에피소드 완료 여부를 줍니다. 에이전트가 목적지에 도달하면 에피소드가 완료됩니다. 받아온 다음 상태로 에이전트로부터 다음상태에서 행동할 행동을 받아옵니다. 그리고 이 정보들로 에이전트를 학습시킵니다. 그리고 받은 보상을 score에 저장합니다.
에피소드가 끝나면 while문을 나와서 scores에 저장하고, 진행상황을 프린트합니다. 코랩에서 실행해보면 10000번의 에피소드를 진행하는데 대략 32분정도 나왔습니다.
학습하는 중에는 아래와 같이 출력됩니다.
epi-9105:score--1.100000000000001:epsilon0.21211477630568779
epi-9106:score--2.8000000000000007:epsilon0.21207659889113592
epi-9107:score--0.4:epsilon0.21204691009711113
epi-9108:score--1.1000000000000005:epsilon0.2120235861032236
epi-9109:score--2.000000000000001:epsilon0.21200238469869406
epi-9110:score--2.1000000000000005:epsilon0.21197906560235544
epi-9111:score-0.20000000000000007:epsilon0.21196210787063685
epi-9112:score--0.9:epsilon0.2119430320439744
epi-9113:score--1.2000000000000002:epsilon0.21191760027890663
epi-9114:score--0.9000000000000007:epsilon0.21189852845776716
epi-9115:score--2.000000000000001:epsilon0.2118773395584394
epi-9116:score-1.1102230246251565e-16:epsilon0.21185615277790623
epi-9117:score--1.0000000000000009:epsilon0.21183496811595584
epi-9118:score--0.19999999999999984:epsilon0.21180954931784624
epi-9119:score--1.0000000000000009:epsilon0.2117883693160321
epi-9120:score-0.20000000000000007:epsilon0.21177142683948247
epi-9121:score--2.5000000000000004:epsilon0.21173966334896033
epi-9122:score--0.8000000000000002:epsilon0.21172272476875165
epi-9123:score--1.9000000000000004:epsilon0.2117036704857066
epi-9124:score-1.1102230246251565e-16:epsilon0.21168250107129918
epi-9125:score--3.2999999999999994:epsilon0.211654983997223
epi-9126:score--1.9000000000000004:epsilon0.21163593581060347
epi-9127:score--2.2000000000000006:epsilon0.21161054089505696
epi-9128:score--2.100000000000001:epsilon0.21158726489938173
epi-9129:score--1.3000000000000007:epsilon0.21155976020526507
epi-9130:score-1.1102230246251565e-16:epsilon0.21153860518123818
epi-9131:score--2.200000000000001:epsilon0.2115132219447248
epi-9132:score--0.29999999999999993:epsilon0.21148572687561476
epi-9133:score--0.5000000000000001:epsilon0.2114540062370875
epi-9134:score-1.1102230246251565e-16:epsilon0.21143286178798154
epi-9135:score-0.20000000000000007:epsilon0.21141594775103875
epi-9136:score--2.700000000000001:epsilon0.21138000991503433
epi-9137:score--2.400000000000001:epsilon0.21135041863712753
그럼 학습 그래프를 한번 확인해 보겠습니다.
from matplotlib import pyplot as plt
plt.plot(episodes, scores)
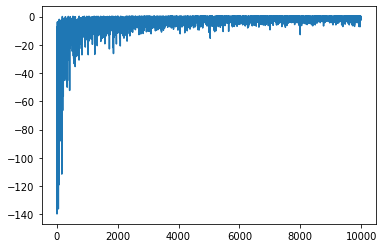
보상이 낮다가 점점 0에 수렴하는 모습을 볼 수 있습니다. 에이전트가 잘 학습을 했다는 것을 볼 수 있습니다. 약간의 잡음이 있는것은 아직 탐험율이 0.2정도로 20% 정도확률로 탐험을 하기 때문에 그런 것으로 이해하면 될 것 같네요. 그럼 이제 학습이 완료된 에이전트가 그리드월드를 돌아다니는 모습을 보겠습니다.
done = False
state = env.reset()
state = np.reshape(state, [1, state_size])
print(state)
while not done:
action = agent.get_action(state)
next_state, reward, done = env.step(action, True)
next_state = np.reshape(next_state, [1, state_size])
state = next_state
env.step()에서 show=True로 했습니다.
state:[0, 1, 4, 3, 1, 1, 4, 2, 2, 4, 3, 3, 4], reward:-0.1, action:v
------------
|# # # # # |
|A > # # # |
|# # > # # |
|# # # > # |
|# # # # G |
------------
state:[0, 2, 4, 2, 2, 0, 4, 3, 1, 4, 4, 2, 3], reward:-0.1, action:v
------------
|# # # # # |
|# # > # # |
|A # # > # |
|# # # # < |
|# # # # G |
------------
state:[0, 3, 4, 1, 3, -1, 4, 4, 0, 3, 3, 1, 3], reward:-0.1, action:v
------------
|# # # # # |
|# # # > # |
|# # # # < |
|A # # < # |
|# # # # G |
------------
state:[1, 3, 3, 1, 4, -2, 3, 3, -1, 3, 2, 0, 3], reward:-0.1, action:>
------------
|# # # # # |
|# # # # < |
|# # # < # |
|# A < # # |
|# # # # G |
------------
state:[1, 4, 3, 0, 2, -2, 3, 1, -1, 3, 0, 0, 3], reward:-0.1, action:v
------------
|# # # # # |
|# # # < # |
|# # < # # |
|# < # # # |
|# A # # G |
------------
state:[2, 4, 2, 0, 1, -3, 3, 0, -2, 3, -1, -1, 4], reward:-0.1, action:>
------------
|# # # # # |
|# # < # # |
|# < # # # |
|> # # # # |
|# # A # G |
------------
state:[3, 4, 1, 0, -1, -3, 3, -2, -2, 4, -1, -1, 4], reward:-0.1, action:>
------------
|# # # # # |
|# < # # # |
|> # # # # |
|# > # # # |
|# # # A G |
------------
state:[3, 4, 1, 0, -3, -3, 4, -2, -2, 4, -1, -1, 4], reward:-0.1, action:O
------------
|# # # # # |
|> # # # # |
|# > # # # |
|# # > # # |
|# # # A G |
------------
state:[4, 4, 0, 0, -2, -3, 4, -1, -2, 4, 0, -1, 4], reward:0.9, action:>
------------
|# # # # # |
|# > # # # |
|# # > # # |
|# # # > # |
|# # # # A |
------------
에이전트가 장애물을 잘 피해서 가는 모습을 볼 수 있습니다!
지금까지 딥살사에 대해서 알아보았습니다.
강화학습 살사 딥살사 딥러닝